Meta提出的ExFM框架,通过解耦师生模型、创新辅助头和学生适配器,成功将万亿参数大模型应用于工业级广告推荐,实现性能持续提升。
原文标题:GPT4规模大模型落地,Meta提ExFM框架:万亿参数基础大模型的工业级落地成为可能
原文作者:机器之心
冷月清谈:
Meta AI 团队提出了 External Large Foundation Model (ExFM) 框架,旨在解决万亿级基础大模型在工业级广告推荐系统中高效落地的问题。该框架通过解耦教师模型和学生模型,并引入数据增强系统(DAS),实现了大模型的低成本部署和迭代。ExFM 还创新地提出了辅助头(Auxiliary Head)和学生适配器(Student Adapter),用以提高知识迁移转化率,并实现了基础模型到多个线上模型的知识迁移。实验结果表明,ExFM 不仅在内部和公开数据集上取得了 SOTA 成果,还在不同领域、任务和阶段的广告排序模型中实现了性能提升,展示了一种新型的 Transfer Scaling Law。
怜星夜思:
1、ExFM 框架中,数据增强系统(DAS)是如何在不影响服务延迟的情况下,确保学生模型(VM)能够及时获取最新的教师模型(FM)知识的?
2、文章中提到,辅助头(Auxiliary Head)的主要作用是解耦真实标签和 FM 预测,从而避免偏差传递。那么,为什么传统蒸馏方法中,将两者通过同一头部融合会导致偏差传递?
3、ExFM 框架在 Transfer Scaling Law 方面有什么创新?为什么说它开启了 "foundation model for RecSys" 领域的新时代?
2、文章中提到,辅助头(Auxiliary Head)的主要作用是解耦真实标签和 FM 预测,从而避免偏差传递。那么,为什么传统蒸馏方法中,将两者通过同一头部融合会导致偏差传递?
3、ExFM 框架在 Transfer Scaling Law 方面有什么创新?为什么说它开启了 "foundation model for RecSys" 领域的新时代?
原文内容

如何让万亿级基础大模型能够高效、低成本地服务于大规模工业级应用,并且让能够随着模型规模的提升(Scaling)而得到持续的性能增长?这一直是众多企业困扰良久的难题。
在线广告推荐系统是互联网平台的核心服务之一,其模型性能直接影响用户体验与商业价值。近年来,随着 GPT-4、 DeepSeek、 Llama 等万亿参数基础模型的成功,工业界和学术界开始探索通过模型规模化(Scaling)的方式建立基础大模型来提升推荐效果。
然而,受限于其巨额训练以及计算成本,以及工业级广告实时推荐对延时性以及部署计算资源的严格要求,基础大模型几乎很难被直接地应用于实时广告排序以及推荐系统,尤其是考虑到很多公司无法负担大规模的 GPU 来服务巨量用户群体。
因此,目前工业界广泛考虑让基础大模型(Foundation Model)的能力迁移到线上小模型(Vertical Model)当中以提高在线模型的能力,且主要采用教师-学生蒸馏(teacher-student distillation)。不过,此类解决方案在广告工业中的应用依旧面临着两大长期被忽视的挑战:受限的训练/推理预算,与动态变化的流式数据分布。这些挑战的存在使得大模型对线上模型的帮助受限,且无法规模化提升线上模型的性能。
本周,在 Meta AI 研究团队提交的一篇论文中,研究团队提出 External Large Foundation Model(ExFM)框架,首次系统性地解决了上述问题,成功支持万亿参数大模型在广告推荐中的高效服务。据文章描述,ExFM 框架实现了以下 SOTA 成果:
-
规模化大模型及线上模型的迭代部署:ExFM 解耦了教师模型和学生模型的迭代和部署,在接近于 0 服务成本的情况下成功部署万亿级别参数的工业级大模型(类 GPT-4 规模),显著降低了工业界受益于大模型的门槛和成本。ExFM 创新的提出数据增强系统(DAS),使得模型在等待线上用户的真实训练标签(ground-truth label, 如用户最终的点击或购买行为)的时间里完成教师模型的参数更新与相应的伪标签预测,达到对服务延迟没有额外要求。
-
高效的知识迁移转化率:ExFM 创新地提出了辅助头(Auxiliary Head)以及学生适配器(Student Adapter)来解耦教师与学生模型,减少流式数据分布变化对教师模型与学生模型训练过程中引入的偏置对知识迁移的影响,从而提高教师模型到学生模型的知识迁移转化率,并对此进行了相应的理论分析。经验结果表明,这两项新技术在内部以及公开数据上皆取得了 SOTA 的结果。
-
实现 1 到 N 的知识迁移转化:在 ExFM 的赋能下,不同领域、任务、阶段里负责广告排序的线上模型均实现了 SOTA 表现。
-
新型的 Transfer Scaling Law:在 ExFM 的赋能下,当不断迭代和提升基础大模型的模型规模时,其高效的知识转化率使得线上的广告排序模型的性能呈现出连续数年的持续提升(图 1),且增速在不断扩大,展示了一种新型的 Transfer Scaling Law。
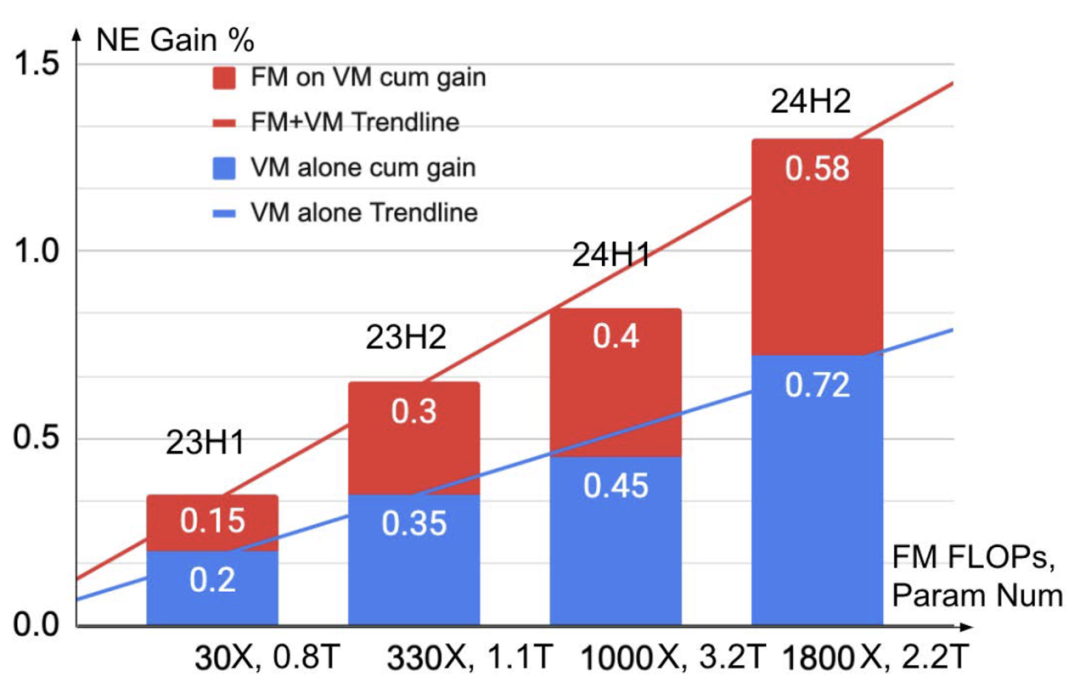
图 1:内部数据上基于不同规模的 FM 对 VM 进行迭代下取得的 NE 增益(时间跨度从 2023 年至 2024 年)。1X 等于 60 Million training FLOPs,1T 指 1 Trillion。
目前该论文已被 WWW 2025 Industrial Track 录用为口头报告 (Oral Presentation,根据往年数据一般为 top 10% 的论文)。本文将深入解析这一技术突破的核心思想与创新实践。

-
论文标题:External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
-
论文链接:https://arxiv.org/abs/2502.17494
规模化的隐形门槛
工业级推荐的两大挑战
现有广告推荐方面的研究多聚焦于模型架构创新与参数规模扩展,但工业场景的特殊性导致线上部署的模型会面临以下两个主要挑战:
1. (C-1) 大流量下严格的延迟限制
-
广告推荐需在毫秒级响应中从海量候选广告(O (100K))中实时筛选,模型推理延迟将直接影响用户体验。
-
传统知识蒸馏(KD)需联合训练师生模型,显著增加计算成本和线上模型更新迭代的延迟,无法满足工业级模型实时更新的需求。
2. (C-2) 流式数据的动态漂移
-
用户与广告数量会出现大规模的实时增减,这导致数据分布持续变化。传统多轮训练易出现过时,具体指的是线上模型更新完成的时间点落后于即时数据到达的时间点而使得大量实时数据无法被纳入训练,导致模型训练后性能不足。并且多轮训练的计算代价高昂,这是因为实时数据的规模异常庞大且与日俱增。
-
教师模型,如基础模型(FM),与垂直模型(VM)间的跨域偏差与新鲜度差异进一步加剧性能衰减。
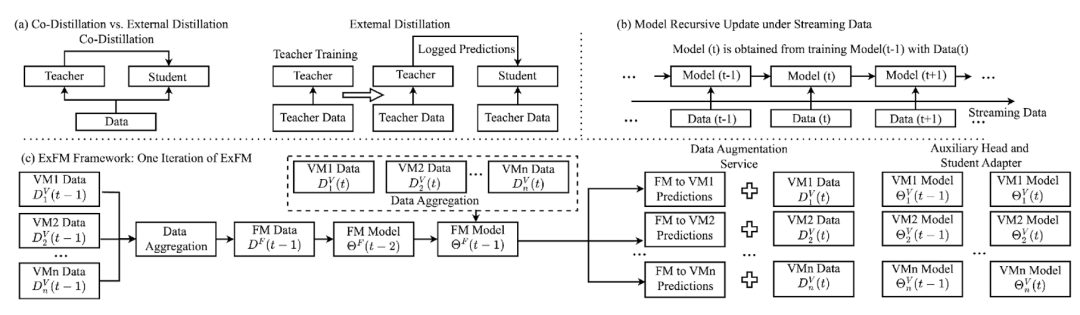 图 2:(a)联合蒸馏(Co-Distillation)与外部蒸馏(External Distillation);(b)流式数据下的模型迭代更新示意图;(c)ExFM 框架,以一次模型迭代为例的示意图。
图 2:(a)联合蒸馏(Co-Distillation)与外部蒸馏(External Distillation);(b)流式数据下的模型迭代更新示意图;(c)ExFM 框架,以一次模型迭代为例的示意图。
对于解决挑战 C-1,常见的解决手段基于知识蒸馏,如果图 2(a)所示,即把一个参数量大的教师模型与一个参数量小的学生模型进行联合训练,而学生模型会用于在线广告推荐。然而在现实场景中,联合训练将增加学生模型的训练复杂度以至于无法满足工业级应用对在线模型进行更新训练的延时要求。另一方面,广告推荐往往涉及多个在线服务模型,每一个模型需要负责特定的阶段的广告排序任务。若对每个服务模型都建立对应的教师模型将非常低效且无法规模化。
因此,本文认为一个理想的教师模型应该满足以下两点需求:
-
教师模型应该独立于学生模型,即进行外部整理,如图 2(a)所示。
-
教师模型应该像一个基础模型一样满足 1-to-N,即一个教师模型可以帮助多个不同方向的学生模型的性能提升。
然而在线广告工业中的流式及动态变化的数据分布(挑战 C-2)使得实现理想的教师模型变得相当困难。如图 2(b)所示,模型需要持续训练以应对不断出现的分布漂移。对此 Meta 内部数据显示,若模型停止更新,其归一化熵损失(NE)随延迟时间呈指数级上升(如图 3 所示)。这迫使工业系统必须在「模型规模」与「服务效率」间寻求平衡。
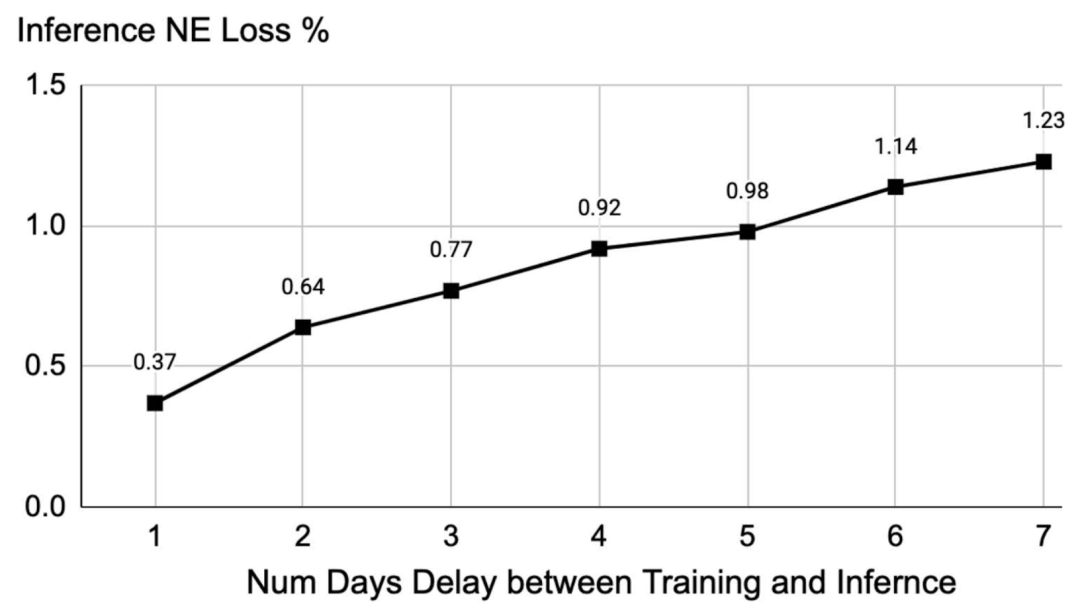 图 3:点击率预测(CTR)随着模型更新延迟而出现严重的下滑。
图 3:点击率预测(CTR)随着模型更新延迟而出现严重的下滑。
为了解决上述的挑战,本文提出 ExFM 框架。ExFM的核心思想是通过外部蒸馏将基础模型(FM)的知识高效迁移至多个垂直模型(VM),并结合动态适配机制应对数据漂移。该框架的核心优势包括:
-
零额外推理延迟:通过外部蒸馏与数据增强系统(DAS),万亿 FM 的预测离线生成,VM 服务延迟与基线持平。
-
动态适应能力:流式训练与适配器设计使模型持续适应数据分布变化,NE 增益能够随着时间推移以更大增速进行扩大。
ExFM 框架
外部蒸馏与动态适应的双重革新
具体而言,ExFM 的技术架构如图 2 (c) 所示,包含四大创新模块:
1. 外部蒸馏与数据增强系统(DAS, 见图 4)
-
解耦师生训练:FM 独立于 VM 训练,通过离线生成预测标签作为监督信号,避免联合训练的计算开销。
-
1:N 资源共享:FM 聚合多个 VM 的数据进行训练,以「基础模型」形式服务多个垂直场景,显著摊薄构建成本。
-
DAS 系统设计:通过分布式快照管理(Zeus)与数据流水线优化,实现 FM 预测的实时记录与高效分发,确保 VM 训练数据始终包含最新 FM 知识。
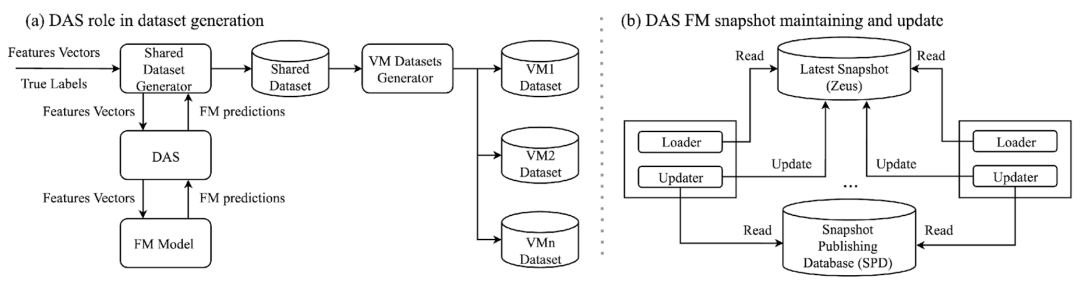 图 4:数据增强系统(Data Augmentation Service,DAS)
图 4:数据增强系统(Data Augmentation Service,DAS)
2. 辅助头
传统蒸馏将 FM 预测与真实标签通过同一头部融合,导致偏差传递。ExFM 创新性引入独立辅助头(图 5a):
-
解耦监督信号:真实标签由服务头处理,FM 预测由辅助头处理,阻断偏差传播路径。
-
梯度/标签缩放技术:通过放大 FM 预测的梯度影响与标签幅值,解决广告点击数据的长尾分布难题。
文中对此进行理论分析显示,辅助头可确保 VM 在真实标签任务上收敛至最优解,而传统单头架构因偏差传递无法实现。
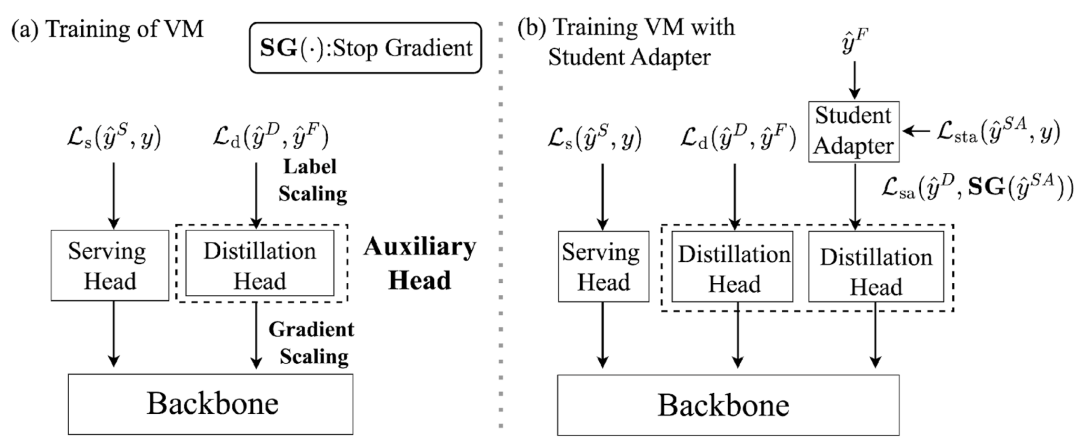 图 5:(a)辅助头(Auxiliary Head)(b)学生适配器(Student Adapter)
图 5:(a)辅助头(Auxiliary Head)(b)学生适配器(Student Adapter)
3. 学生适配器(Student Adapter)
针对 FM 与 VM 间的新鲜度差异,ExFM 提出轻量级适配模块(图 5b):
-
动态校正机制:通过小型 MLP 网络实时调整 FM 预测,使其适配 VM 的当前数据分布。
-
理论保障:文中给出理论分析表明,适配器可将模型偏差降低,显著优于传统方法。
4. 流式训练范式
-
FM 与 VM 均采用单轮流式训练,每日处理超 3000 亿样本,模型参数逐日迭代更新。
-
系统支持分钟级快照切换,确保服务高可用性。
实验结果
性能飞跃与工业验证
ExFM 在 Meta 内部数据集与公开数据集(TaobaoAd、Amazon 等)上均取得显著效果:
1. 单 VM 性能提升
-
内部场景中,3.2 万亿参数的 FM 使 VM 的归一化熵(NE)持续降低,性能增益随训练数据量增长呈类指数上升(图 1)。
-
公开数据集上(表 1),ExFM 在不同 FM-VM 组合均取得性能的提升。
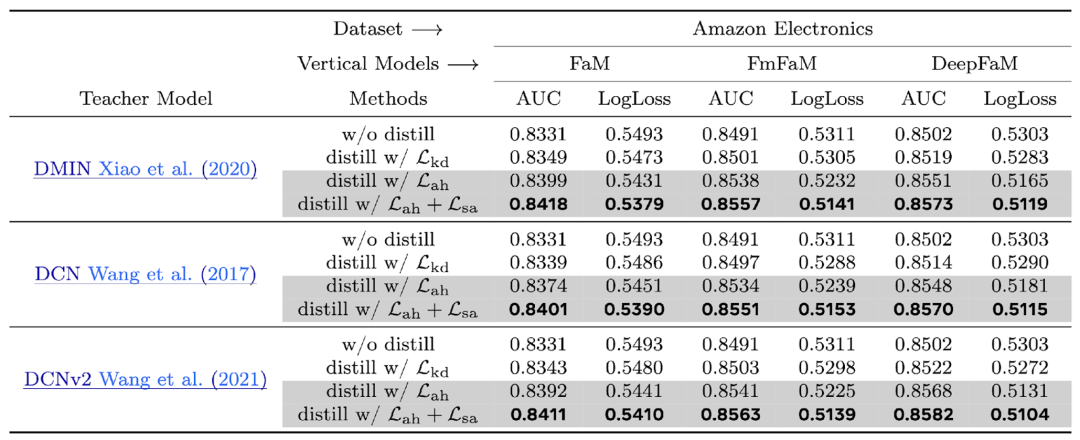 表 1:公开数据集上的表现
表 1:公开数据集上的表现
2. 跨场景泛化能力
-
单一 FM 可同时服务广告系统的召回、粗排、精排多阶段 VM(图 6),NE 增益达 0.11%-0.25%。
-
在跨域(表 4)与多任务(表 5)场景中,ExFM 均显著优于无 FM 基线,验证其通用性。
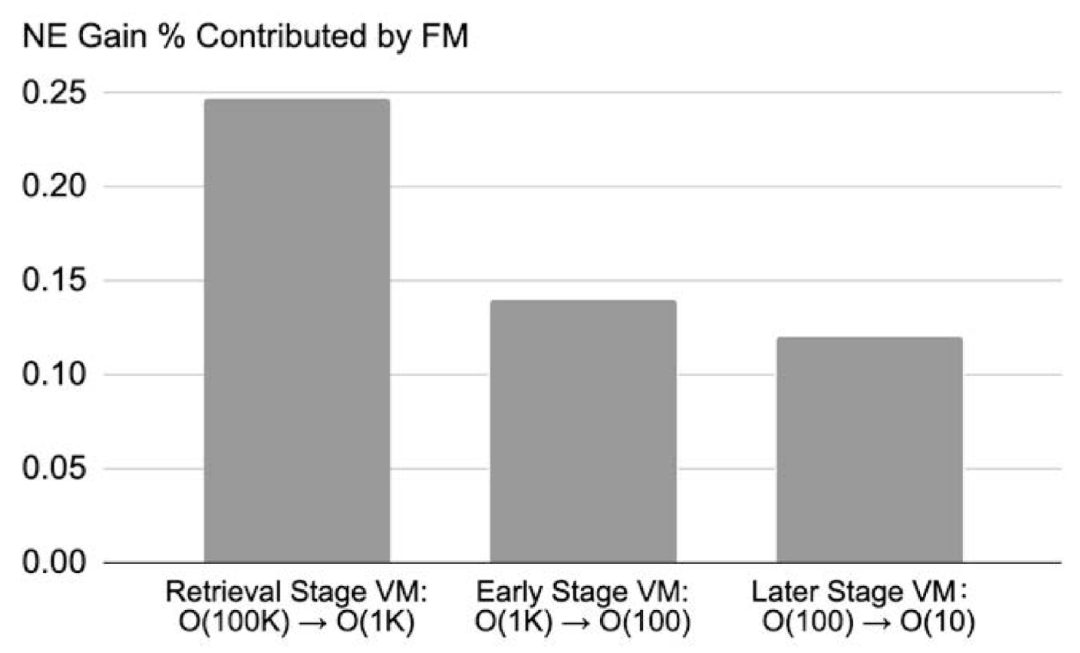 图 6:内部数据上 1000X,3.2T FM 对 跨阶段(cross-stage) VM 的 NE 增益
图 6:内部数据上 1000X,3.2T FM 对 跨阶段(cross-stage) VM 的 NE 增益
 表 4(左)及 表 5(右):公开数据集上 FM 对跨域以及跨任务的 VM 的性能提升
表 4(左)及 表 5(右):公开数据集上 FM 对跨域以及跨任务的 VM 的性能提升
3. 模块消融实验
-
辅助头(AH)贡献主要性能增益,使学生模型 NE 降低 4%(图 7)。
-
学生适配器(SA)在 FM 更新延迟时仍能维持 0.08% 的 NE 增益(图 8),但其效果依赖 FM 的持续迭代(图 9)。
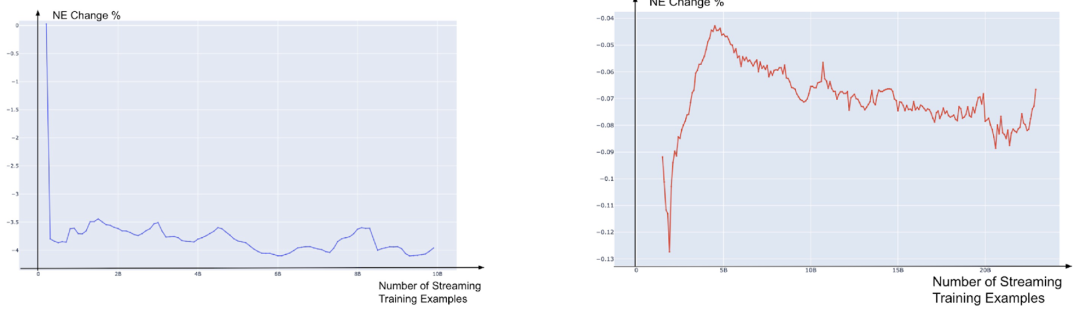 图 7(左):对 1000X 3.2T 的 FM 增加辅助头(AH)后的 NE 变化; 图 8(右):对 1800X,2.2T 的 FM 增加学生适配器(SA)后的 NE 变化
图 7(左):对 1000X 3.2T 的 FM 增加辅助头(AH)后的 NE 变化; 图 8(右):对 1800X,2.2T 的 FM 增加学生适配器(SA)后的 NE 变化
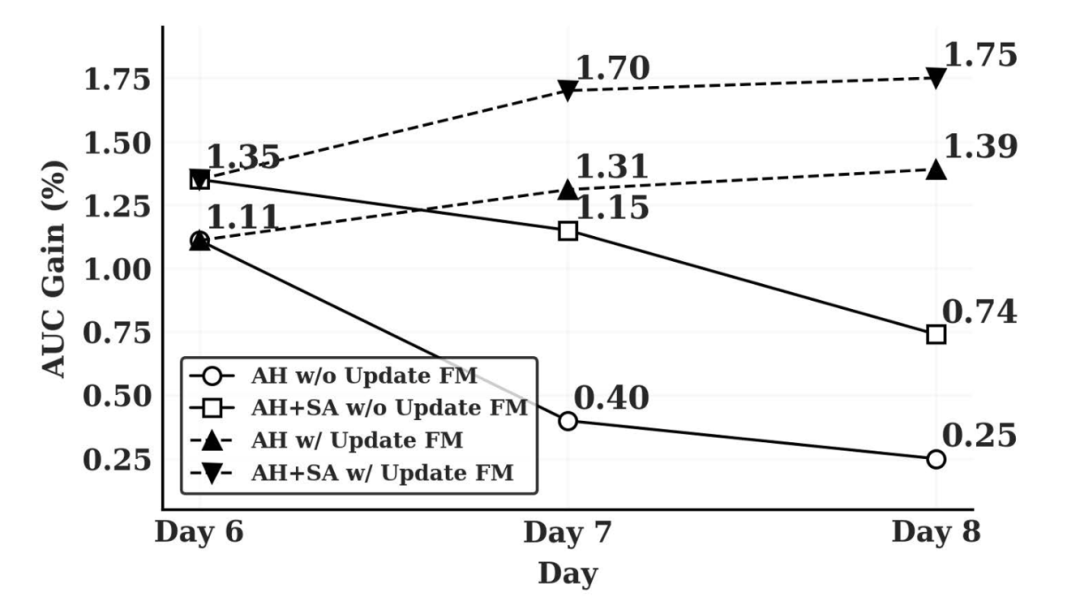 图 9:公开数据集上,当 FM 的更新出现延迟的时,学生适配器的性能变化
图 9:公开数据集上,当 FM 的更新出现延迟的时,学生适配器的性能变化
结论
在本论文中,Meta AI 研究团队提出了 ExFM 框架以实现万亿参数量的基础大模型对实时广告推荐模型进行持续、规模化的性能提升。降低了LLM规模的大模型在 recsys domain 的门槛,开启了「foundation model for RecSys 」领域的时代。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]