香港科技大学开源7B形式化推理模型,媲美DeepSeek-R1。通过任务拆解和微调,小模型也能在形式化验证领域取得显著成果。
原文标题:7B级形式化推理与验证小模型,媲美满血版DeepSeek-R1,全面开源!
原文作者:机器之心
冷月清谈:
怜星夜思:
2、文章里提到,形式化数据微调后,模型在数学、推理和编程任务上的性能也得到了提升。这是不是意味着,不同类型的AI任务之间存在某种通用的“底层逻辑”?我们能不能通过训练一种模型,让它同时擅长多个领域的任务?
3、文章提到模型在ACSL语言上表现最好,是因为ACSL更贴近自然语言且语法类似C语言。这是否意味着,形式化语言的设计应该尽量贴近自然语言和常用编程语言?这对未来的编程语言设计有什么启示?
原文内容

随着 DeepSeek-R1 的流行与 AI4Math 研究的深入,大模型在辅助形式化证明写作方面的需求日益增长。作为数学推理最直接的应用场景,形式化推理与验证(formal reasoning and verification),也获得持续关注。
然而,近期的形式化推理大模型大多只针对单一形式化语言模型,缺乏对多形式化语言、多形式化任务场景的深度探索。
近日,由香港科技大学牵头,联合中科院软件所、西安电子科技大学、重庆大学等单位,开源了一系列形式化推理与验证大模型,仅用 7B,即可在相关任务上获得与 671B 满血版 DeepSeek-R1 相当的水平!

-
论文标题:From Informal to Formal–Incorporating and Evaluating LLMs on Natural Language Requirements to Verifiable Formal Proofs
-
论文链接:https://arxiv.org/abs/2501.16207
-
Hugging Face 模型链接:https://huggingface.co/fm-universe
正如 Meta FAIR 和斯坦福大学等多所机构在去年年底的立场论文(Formal Mathematical Reasoning: A New Frontier in AI)中所指出的,多语言形式化验证模型正日益成为业界发展的趋势。
事实上,形式化验证(formal verification)不仅是计算机科学的核心问题,也是形式化数学最直接的应用之一。然而,由于其门槛高、人力消耗大和部署成本高,形式化验证的普及与推广一直受到限制。
凭借大模型在语义理解、代码自动生成等方面的优势,引入该技术有望大幅加速验证流程,从而有效降低人力成本并提升自动验证效率。
形式化任务拆解
研究团队首先对形式化验证任务进行了分层拆解,从非形式化的自然语言输入到可验证的形式化证明(formal proof)或可检测的模型(model checking)。在此基础上,研究团队将传统的端到端形式化验证流程细化为六个子任务,包括验证需求分解、形式化规约片段生成、规约补全、填空,以及代码到形式化规约的自动生成。

图 1 形式化验证任务拆解
这一过程可以与代码生成(code generation)任务相对照:代码生成任务旨在将自然语言描述的功能转换为相应的代码实现,而形式化证明生成或模型生成(formal proof/model generation)则将自然语言描述的验证需求转化为由形式化语言编写的形式化证明(proof)或模型(model)。

图 2 从代码生成到形式化证明生成
研究团队从 Github 收集了五种形式化语言的经过一系列数据收集、清洗与整理,最终得到了 14k 数据用于训练微调(fm-alpaca),4k 数据用于测试(fm-bench)。

图 3 数据准备过程
大模型在形式化细分任务上的能力对比
通过对五种形式化语言(Coq, Lean4, Dafny, ACSL, TLA+)在形式化证明写作上六种细分能力对比,研究团队获得了一些有趣的发现。
从形式化任务的角度(如图 4),未经微调的通用指令大模型更擅长从代码生成形式化证明(准确率 43.57%),而不擅长从自然语言生成形式化证明(8.65%~10.61%),远低于代码生成任务(从自然语言生成编程语言如 Python)。
满血版(671B)DeepSeek-R1 平均准确率为 27.11%,而其他参数规模在 8B 至 72B 的模型平均准确率仅介于 7.32% 与 18.39% 之间。
另外,研究团队观察到在形式化规约填空的任务中,较大规模的模型往往不及小规模模型。例如,70B 的 llama3.1-instruct 模型在填空(列「ProofInfill」)上的准确率仅为 8B 模型的一半。这一现象可能与这些模型的微调策略:指令模型被训练得更擅长生成,而非填空。研究团队还发现,尽管 70B 级规模模型填写的形式化规约片段看似更加正确,但因常常包含额外的内容,导致「说多错多」,因此最终的准确率反而不如小模型。

图 4 验证任务上的差异(微调前)
大模型在不同形式化语言上的能力对比
从形式化语言的角度看(见图 5),大模型在 ACSL 上的效果最好(34.92%),Dafny 次之(15.92%)。研究团队认为,原因可能在于:一方面,ACSL 语言的关键词更贴近自然语言,其语法结构又类似于 C 语言,使得生成过程更为顺畅;另一方面,ACSL 规约片段相对较短,而 Coq 和 TLA 等语言的规约片段较长,生成难度更大。
图 5 还显示,仅通过增加生成次数(从 1 次提升至 5 次),即可在不用微调的情况下,得到 10.82%~63.64% 的提升。之后,进一步结合上下文学习(in-context learning),可以进一步将准确率翻番(51.33%~532.83%)。

图 5 形式化语言上的差异(微调前)
微调带来的能力提升
接下来,研究团队在 3 个 7~8B 的基础模型(LLaMA-3.1,Qwen-2.5,Deepseek-coder-v1.5)上用 fm-alpaca(14k 数据),同时对比了普通的对话型指令微调数据集 tulu-v3 和 ultra-chat。
如图 6,经过形式化数据 fm-alpaca 微调之后,大模型在各类形式化任务上均有明显提升(模型名以「fma」为后缀的模型),性能几乎翻倍。
值得注意的是,这种显著提升仅用了 14k 条形式化相关的指令数据(instruction-response pairs)。
有趣的是,当把形式化数据和对话型指令数据混合微调时,能进一步提升模型性能,从 21.79%(仅用 fm-alpaca 微调)提升至 23.75%(fm-alpaca + ultrachat)和 25.16%(fm-alpaca + tulu)。
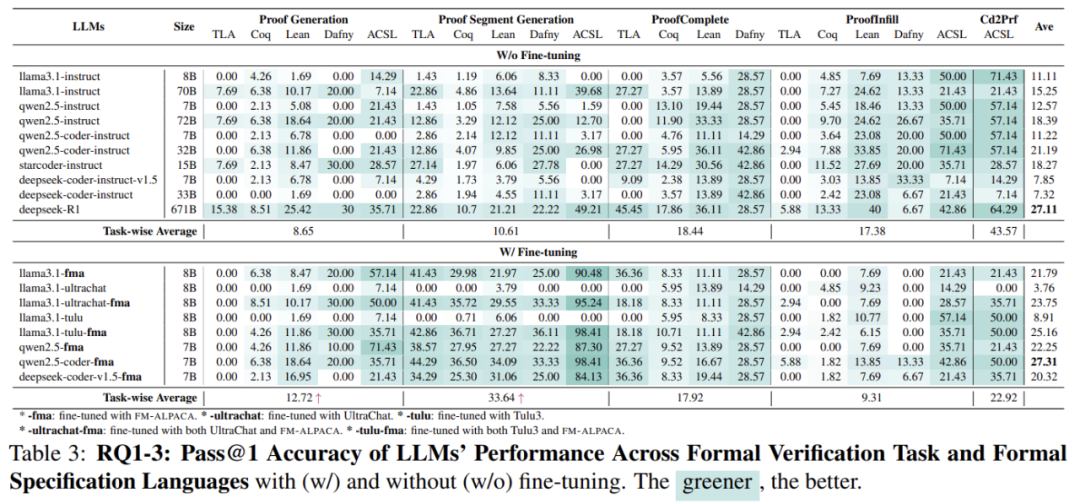
图 6 微调前后结果对比
对比图 5 与图 6 还可以发现,尽管增加迭代次数和上下文学习可以提升准确率,但仍比不上微调带来的提升。
能力迁移探究
最后,研究团队进一步探索了形式化数据微调对大模型数学、推理和编程等任务上的「迁移能力」。他们通过对比微调前后在上述任务上的表现差异,以验证大模型能否通过形式化验证能力训练中习得推理、数学等「元能力」。
实验结果令人惊喜:利用形式化数据(FM-Alpaca)进行微调后,模型在数学、推理、代码任务上的平均性能平均性能提升达到了 1.37% 至 5.15%。
该观察或为未来探索模型「元能力」、「能力迁移」提供启发。

总结
-
高质量数据集构建:研究团队构建了包含 18000 对高质量指令 - 响应对的微调数据集(fm-alpaca)与评估集(fm-bench),覆盖 5 种主流的形式化语言(Coq, Lean4, Dafny, ACSL, TLA+)和 6 种不同形式化推理与验证任务;
-
形式化任务分解与评估:将从非形式化的自然语言需求到形式化、可验证的证明的转换过程细分为六个子任务,明确了每一步的目标和挑战,有助于精确定位大模型的能力瓶颈;
-
微调模型开源:通过微调,7~8B 的小模型在生成形式化证明的能力得到显著提升,模型的性能提高了近三倍,在评估任务上媲美 671B 满血版 DeepSeek-R1;
-
后续启发与影响:基于三种基础模型的微调模型均已开源;完整的执行上下文和自动验证流程也将开源,这将有助于降低形式化验证的门槛,减少人力消耗及部署成本。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com