上海AI Lab推出MoM模型,赋予线性注意力稀疏记忆能力,提升其在记忆密集型任务上的性能,推理速度表现出色。
原文标题:上海AI Lab最新推出Mixture-of-Memories:线性注意力也有稀疏记忆了
原文作者:机器之心
冷月清谈:
上海AI Lab最新推出的Mixture-of-Memories (MoM)模型,旨在解决线性序列建模方法内存大小受限的问题,并提升其在记忆密集型任务上的性能。MoM的核心思想是通过路由机制为每个token分配多个稀疏激活的记忆单元,并引入一个共享记忆单元来处理全局信息。每个记忆单元采用RNN-style计算,保持了线性时间复杂度的训练效率和常数级复杂度的推理效率。实验结果表明,MoM在in-context recall-intensive任务上表现出色,甚至在1.3B模型规模上可以与Transformer架构媲美。
怜星夜思:
1、MoM 中提到的 shared memory 设计,感觉和单头注意力有点像,都是提取全局信息,那么它和单头注意力的区别主要是什么?
2、MoM 的 router 机制是如何避免将相似的 token 分配到相同的 memory,从而降低模型的泛化能力?
3、文章中提到MoM在1.3B模型规模上已经可以和Transformer媲美,这是否意味着MoM可以完全替代Transformer?
2、MoM 的 router 机制是如何避免将相似的 token 分配到相同的 memory,从而降低模型的泛化能力?
3、文章中提到MoM在1.3B模型规模上已经可以和Transformer媲美,这是否意味着MoM可以完全替代Transformer?
原文内容
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
回顾 AGI 的爆发,从最初的 pre-training (model/data) scaling,到 post-training (SFT/RLHF) scaling,再到 reasoning (RL) scaling,找到正确的 scaling 维度始终是问题的本质。2017 年发布的 Transformer 架构沿用至今,离不开 Transformer 强大的 “无损记忆” 能力,当然也需要付出巨大的 KV 缓存代价。换句话说,Transformer 架构具有强大的 memory scaling 能力。
DeepSeek NSA 通过三种方式压缩 “KV” 实现 sparse attention,但这只是一种可以工作但不优雅的折中方案。因为它在压缩 Transfromer 的记忆能力,以换取效率。
另一方面,大概从 2023 年火到今天的线性序列建模方法(包括 linear attention 类,Mamba 系列,RWKV 系列)则是另一个极端,只维护一份固定大小 dxd 的 RNN memory state,然后加 gate,改更新规则,但这种方式始终面临较低的性能上限,所以才会有各种混合架构的同样可以工作但不优雅的折中方案。
我们认为,未来的模型架构一定具有两点特性:强大的 memory scaling 能力 + 关于序列长度的低复杂度。后者可以通过高效注意力机制实现,比如:linear 或者 sparse attention,是实现长序列建模的必备性质。而前者仍然是一个有待探索的重要课题,我们把给出的方案称为 “sparse memory”。
这促使我们设计了 MoM: Mixture-of-Memories,它让我们从目前主流线性序列建模方法改 gate 和 RNN 更新规则的套路中跳脱出来,稀疏且无限制地扩大 memory 大小。MoM 通过 router 分发 token(灵感来自 MoE)维护多个 KV memory,实现 memory 维度 scaling。每个 memory 又可以进行 RNN-style 计算,所以整体具有关于序列长度线性的训练复杂度,推理又是常数级复杂度。此外,我们又设计了 shared memory 和 local memory 合作分别处理全局和局部信息。实验表现相当惊艳,尤其是在目前 linear 类方法效果不好的 recall-instensive 任务上表现格外好,甚至在 1.3B 模型上已经和 Transformer 架构旗鼓相当。

-
论文地址:https://arxiv.org/abs/2502.13685
-
代码地址:https://github.com/OpenSparseLLMs/MoM
-
未来还会集成在:https://github.com/OpenSparseLLMs/Linear-MoE
-
模型权重开源在:https://huggingface.co/linear-moe-hub
方法细节
Linear Recurrent Memory
对于这部分内容,熟悉线性序列建模的小伙伴可以跳过了。
输入  经过 query key value proj 得到
经过 query key value proj 得到 :
:
经过 query key value proj 得到
最简洁的 recurrent 形式线性序列建模方法(对标最基础的 linear attention)按照下面公式做 RNN 更新:

这里,我们不得不提一下,各种各样的 Gate 形式( 前面的)和更新规则( 右边的)就是在魔改上面的一行公式,各种具体形式如下表:
前面的)和更新规则( 右边的)就是在魔改上面的一行公式,各种具体形式如下表:
(各种方法本身有不同的符号,像 Mamba, HGRN 就不用 q k v,这里为了统一对比全部对标到 linear attention 形式。其中Titans的形式,把 memory update rule 看作 optimzier update 的话,最核心的还是 SGD 形式,暂时忽略momentum/weight decay ,只一个公式表达的话写成这种梯度更新的形式是合理的。)

其实这些方法又可以进一步细分为不同类别(很多地方都粗略的统一称为 linear RNN 或者 RNN),这里论文暂时没提:
-
Linear Attention, Lightning Attention, RetNet, GLA, DeltaNet, Gated DeltaNet 属于 linear attention 类
-
Mamba2 属于 SSM 类,HGRN2 属于 linear RNN 类
-
TTT, Titans 属于 Test-Time Training 类
Mixture-of-Memories
MoM 思路非常简单,和 MoE 一样按照 token 分发,通过 router 为每个 token 选择 topk 的 memories 并计算各自权重:

所有激活的 topk memories 按照各自权重加权求和得到一份混合记忆:

然后就又回到了 linear 类方法一贯的输出计算:

另外,这里我们额外引入了 shared memory 的概念,即每个 token 都会经过这个永远激活的 memory,有利于模型获取全局信息。相对而言,其他稀疏激活的 memory 更擅长获取局部信息。消融实验表明,shared memory 的存在对模型效果有明确的积极作用。

硬件高效实现
MoM的硬件高效Triton算子可以很方便地实现,其输出的计算可以简单写作:

也就是说 MoM 中每个 memory 的计算过程可以复用现有的单个算子,再把所有 memory 的输出加权求和起来。和直接在算子内先求和再算输出是数学等价的。
实验结果
in-context recall-instensive tasks
一直以来,线性序列建模方法因为自身非常有限的 memory 大小,在这类 in-context recall-intensive 任务上表现不好。同时 Transformer 模型得益于其强大的无损记忆能力,非常擅长这类任务。所以已经出现了各种层间 hybrid 的模型,来提升 linear 类模型在这类任务上的效果。
我们首先重点测试了这类任务(结果见下表),使用 Gated DeltaNet 作为 MoM 的 memory 计算形式(在 Memory 更新过程中,每个 memory 都使用 Gated DeltaNet 的 gate 和更新规则),总共 4 个 local sparse memory,激活 2 个,还有一个 shared memory。其中标 † 的模型来自开源项目(https://huggingface.co/fla-hub),没标 †的是我们从头预训练的模型。
结果还算相当不错,在没有数据污染或任何套路的情况下,结果显示 MoM 就是单纯地效果好。这也和预期一致,翻倍扩展 memory 大小,效果好过其他 linear 类方法。有一些意外的是,在 1.3B 的结果里,MoM 基本可以和 Transformer 相媲美。

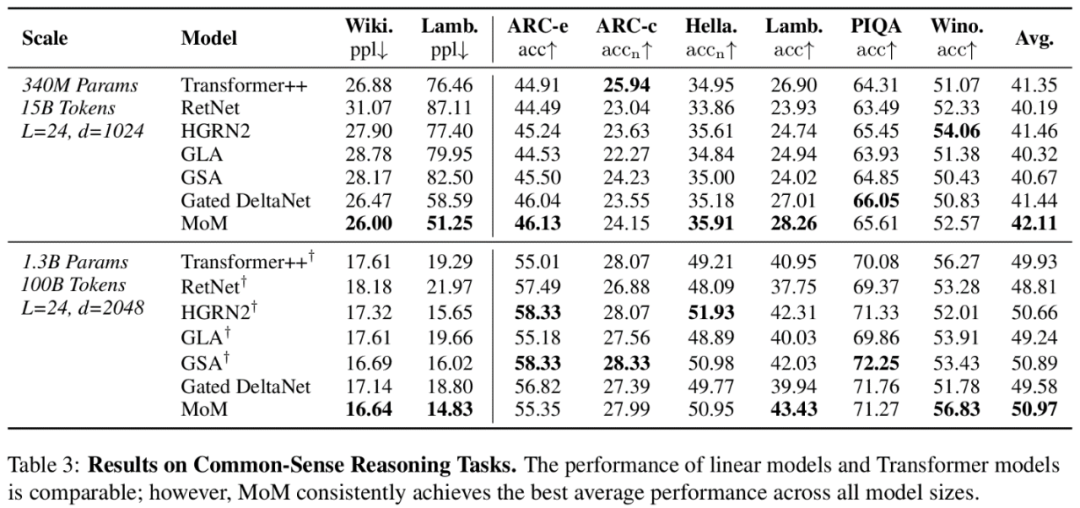
其他评测效果
其他评测结果效果也不错:

推理效率
推理效率是线性序列建模方法的重点,结果显示 MoM 在常数级复杂度推理速度和显存占用方面,表现出强大的优势。

消融实验


Loss 曲线

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com