一种多LLM协作摘要长文本的新方法,显著提升摘要质量,性能提升高达3倍。
原文标题:面向长文本的多模型协作摘要架构:多LLM文本摘要方法
原文作者:数据派THU
冷月清谈:
怜星夜思:
2、文章中提到多LLM方法比单一LLM效果提升显著,这种提升主要来自哪些方面?
3、除了文章中提到的方法,还有哪些技术可以用于长文本摘要?它们各自的适用场景是什么?
原文内容

来源:DeepHub IMBA本文约2800字,建议阅读5分钟
本文介绍了面向长文本的多模型协作摘要架构的文本摘要方法。
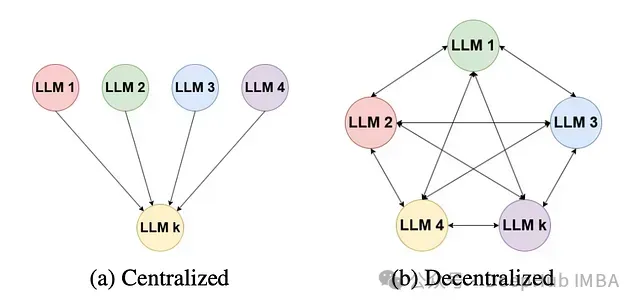
集中式多LLM摘要

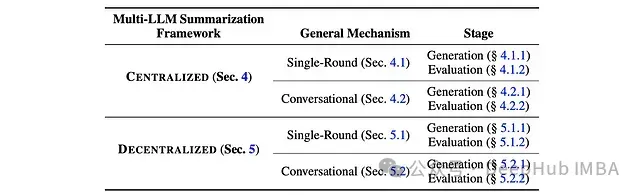
单轮处理

对话式处理


分散式多LLM摘要

单轮处理

对话式处理
实验设置

评估结果
-
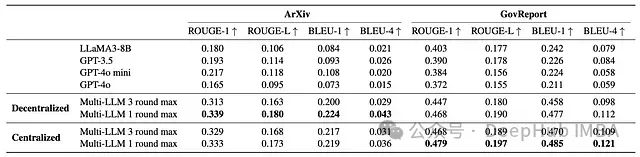
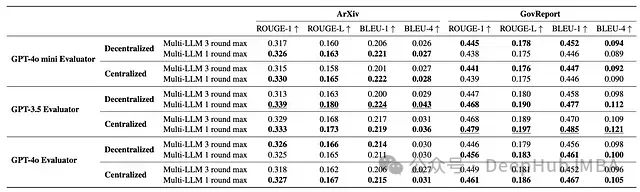
多LLM框架显著优于单一LLM基准,在某些情况下性能提升高达3倍
-
集中式多LLM方法平均提升得分73%,而分散式方法平均提升70%
-
仅使用两个LLM和单轮生成评估就能获得显著的性能提升,表明该方法具有成本效益
-
该框架在不同的中央模型(评估器)和决胜模型中表现稳定
-
超过两个LLM和额外的生成评估轮次并未带来进一步改进
实现代码
from langchain_ollama import ChatOllamagemma2 = ChatOllama(model=“gemma2:9b”, temperature=0)
llama3 = ChatOllama(model=“llama3:8b”, temperature=0)
llama3_1 = ChatOllama(model=“llama3.1:8b”, temperature=0)prompt_initial_summary = “”"
Provide a concise summary of the text in around 160 words.
Output the summary text only and nothing else.
提示词
prompt_initial_summary = “”"
Provide a concise summary of the text in around 160 words.
Output the summary text only and nothing else.{text}“”".strip()
prompt_subsequent_summary = “”"
Given the original text below, along with the summaries of that text by 3 LLMs,
please generate a better summary of the original text in about 160 words.
ORIGINAL:{text}Summary by agent_1:
{summary_1}Summary by agent_2:
{summary_2}Summary by agent_3:
{summary_3}“”".strip()
prompt_decentralised_evaluation = “”"
Given the original text below, along with the summaries of that text by 3 agents,
please evaluate the summaries and output the name of the agent that has the best summary.
Output the exact name only and nothing else.
ORIGINAL:{text}Summary by agent_1:
{summary_1}Summary by agent_2:
{summary_2}Summary by agent_3:
{summary_3}“”".strip()
prompt_centralised_evaluation = “”"
Given the initial text below, along with the summaries of that text by 3 LLMs,
please evaluate the generated summaries and output the name of the LLM has the best summary.
On a separate line indicate a confidence level between 0 and 10.ORIGINAL:
{text}Summary by agent_1:
{summary_1}Summary by agent_2:
{summary_2}Summary by agent_3:
{summary_3}Remember, on a separate line indicate a confidence level between 0 and 10.
“”".strip()prompt_concate = “”"
Provide a concise summary of the text in around 160 words.
Output the summary text only and nothing else.{summaries}“”".strip()
汇总
class SingleTurnCentralised():
def init(self, models):
self.models = modelsdef generate(self, text):
summaries =
for model in self.models:
summaries.append(model.invoke([{“role”: “user”, “content”: prompt_initial_summary.format(text=text)}]).content)
return summariesdef evaluate(self, text, summaries):
response = gemma2.invoke([
{“role”: “user”, “content”: prompt_centralised_evaluation.format(text=text, summary_1=summaries[0], summary_2=summaries[1], summary_3=summaries[2])}
]).content
winner, *_, confidence = response.split()
return winner, confidencedef call(self, chunks):
summarised_chunks =
for chunk in chunks:
summaries = self.generate(chunk)
winner, confidence = self.evaluate(chunk, summaries)
summarised_chunks.append(summaries[int(winner[-1]) -1])final_summary = gemma2.invoke([{“role”: “user”, “content”: prompt_concate.format(summaries=“\n”.join(summarised_chunks))}]).content
return final_summary
single_turn_centralised = SingleTurnCentralised([gemma2, llama3, llama3_1])
final_summary = single_turn_centralised(chunks)
论文地址:
Multi-LLM Text Summarization
https://arxiv.org/abs/2412.15487
