阿里推出EMO2模型,可根据音频生成更逼真的人像视频,动作表情更自然,手势更流畅。
原文标题:真假难辨!阿里升级AI人像视频生成,表情动作直逼专业水准
原文作者:机器之心
冷月清谈:
阿里巴巴通义实验室升级了AI人像视频生成模型EMO2,只需提供一张人像图片和一段音频,即可生成表情动作更自然流畅的视频。EMO2的改进主要体现在两个方面:一、它着重关注手部动作与音频的关联,先生成与音频一致的手势;二、它利用“具有像素先验知识的IK”方法,使生成的身体动作更协调自然。EMO2生成的视频在动作幅度、多样性和清晰度方面都超越了以往的方法,尤其在手势的自然度和表现力上提升显著。该模型在虚拟主播、数字人交互等领域具有广阔的应用前景。
怜星夜思:
1、EMO2专注于手部动作生成,这是否意味着未来AI生成的视频会更注重肢体语言的表达?
2、EMO2的技术方案中提到的“具有像素先验知识的IK”方法,具体是如何将人体结构知识融入像素生成的?
3、除了虚拟主播和数字人交互,EMO2这项技术还能应用于哪些领域?
2、EMO2的技术方案中提到的“具有像素先验知识的IK”方法,具体是如何将人体结构知识融入像素生成的?
3、除了虚拟主播和数字人交互,EMO2这项技术还能应用于哪些领域?
原文内容
![]()
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
EMO 最初由阿里巴巴通义实验室提出,作为音频驱动高表现力人像 AI 视频生成的先驱。现在,该实验室的研究者带来了升级版本「EMO2」!
只需提供一张人物的肖像图片,你就可以输入任意长度的音频来驱动人物说话、唱歌或进行手势舞。并且,生成的人物表情和动作都具备高度的感染力和专业水准。

-
论文标题:EMO2: End-Effector Guided Audio-Driven Avatar Video Generation
-
论文地址:https://arxiv.org/abs/2501.10687
-
项目地址:https://humanaigc.github.io/emote-portrait-alive-2/
我们来看几个视频生成示例:
1. 研究问题
AI 技术发展已经实现了通过音频驱动人物面部表情的能力,但在虚拟主播、数字人交互等新兴领域,如何让 AI 通过音频自动生成自然流畅的动作肢体语言和表情,始终是业界关注的技术焦点。
以往的方法可能难以通过音频驱动生成流畅自然的手部动作,可能存在肢体错乱或者动作幅度不够大,表现力不够高的问题。
这一领域的一个基本挑战在于人类身体的复杂性,其作为一个多关节的复杂系统,比较难实现对于复杂丰富动作的驱动。以往的音频驱动人体动作生成的方法在捕捉自然动作中多个关节的复杂耦合方面表现不足,导致效果欠佳。研究者表明,音频与不同身体关节之间的关联差异显著。

受启发于机器人控制系统对人类行为的模仿:机器人往往具有一个「末端执行器」(end effector),比如机械手、钻头甚至足部等,它会在特定任务中将末端执行器移动到指定 pose,同时带动其他结构部分动作,这些其他部分关节的角度往往通过逆向运动学(IK)来获取。机器人的控制大多会关注于末端执行器上。
因此,研究者希望重新定义语音-人类动作生成这一任务的目标。手作为日常生活中的「末端执行器」(end effector),与人类意图更紧密相关,并且与音频之间的关系显著。比如,当人类说话或唱歌时,往往会伴随意图明确的手势。因此,建立音频与手部动作的联系会更加简单直接。
然而,类似于机器人控制,通过逆向运动学(IK)来获得其他人体关节角度时,可能会出现奇异性,导致错误的运动规划结果,EMO2 指出,视频生成模型往往具备一定生成人体结构的能力,因此 EMO2 提出可以将人体结构知识融入像素生成,即「具有像素先验知识的 IK」(Pixels Prior IK)。
最终,EMO2 通过音频生成手部动作,然后利用 2D 视频模型生成其他身体部位,从而实现自然高表现力的人物动作视频生成。
2. 技术方案
基于此灵感,研究者提出了一套两阶段的解决方案,用于音频驱动的手势及面部表情生成。
在第一阶段,专注于建立音频到手部动作的映射,基于 DIT 模型,借助音频与手部动作之间的强相关性,生成具有高表现力和高一致性的手势动作。

在第二阶段,研究者使用基于 diffusion UNet 架构的视频生成模型合成视频帧,以第一阶段所生成的动作表征作为引导,生成真实的面部表情和身体动作。
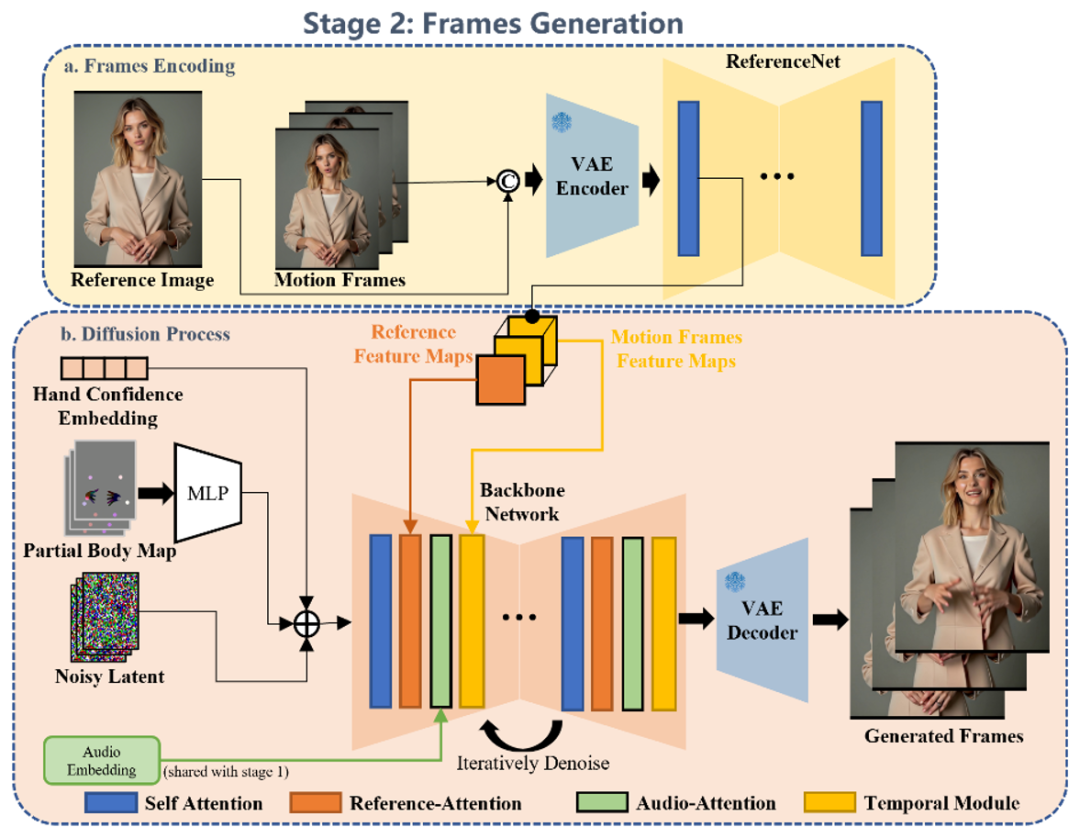
3. 效果对比
EMO2 分别对第一阶段的动作生成和第二阶段的视频生成做了结果对比。
在动作生成方面,EMO2 所生成的动作相比于以往的方法会具有更大运动范围和多样性,且与音频的一致性会更强。
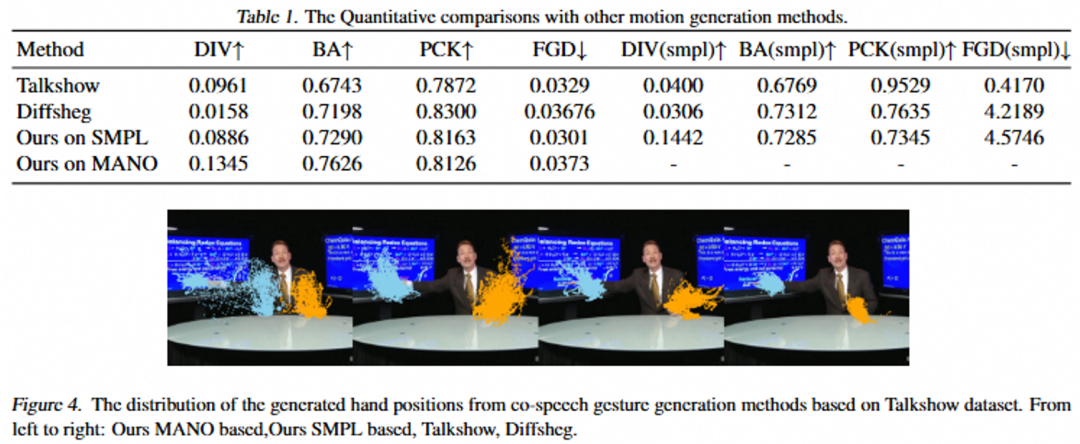
在人物视频生成方面,EMO2 相比以往的方法也存在显著优势,尤其是在手势动作的多样性和手部清晰度上。
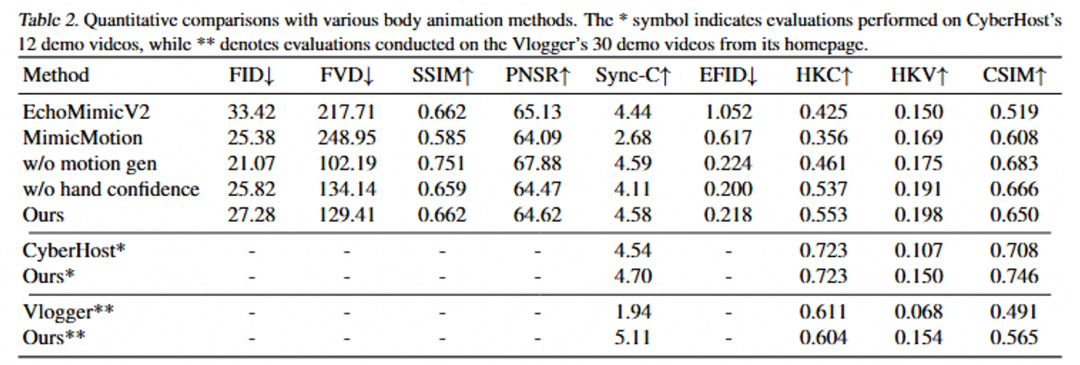
4. 结论
EMO2 提出了一种基于扩散模型的两阶段框架,用于生成与音频同步的人物唱歌 / 讲话 / 手势舞视频。EMO2 扩展了 EMO 模型,使其能够生成上半身动作。EMO2 研究发现,在人类自然活动中,手部动作与其他身体部位相比,与音频信号最为相关。
因此,在第一阶段,EMO2 基于音频仅生成手部动作,然后将动作表征作为第二阶段视频生成中的控制信号使用。实验结果表明,该框架能够生成比其他方法更加生动、富有表现力的人体视频。研究者希望这项工作能为音频驱动视频生成的技术提供新的思路。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com