深入解析SVM核心机制:铰链损失函数的原理、实现及与其他损失函数的比较。
原文标题:深入剖析SVM核心机制:铰链损失函数的原理与代码实现
原文作者:数据派THU
冷月清谈:
本文详细介绍了支持向量机(SVM)的核心——铰链损失函数。铰链损失函数的数学表达式为L(y, f(x)) = max(0, 1 - y·f(x)),其中y为真实标签(-1或1),f(x)为模型预测值。
该函数的核心特性在于其凸性保证了全局最优解,非光滑性与支持向量概念密切相关,而稀疏性则提高了模型泛化能力,最终实现了边际最大化。
铰链损失的工作机制分为三种情况:完全正确分类(y·f(x) ≥ 1)时损失为0;在边际区域内分类(0 < y·f(x) < 1)时,损失随样本靠近决策边界线性增加;错误分类(y·f(x) ≤ 0)时,损失大于1,并随预测值偏离真实标签线性增加。
文章提供了Python代码实现,包括基础实现和向量化优化版本。铰链损失的优势在于最大化分类边际、提高泛化能力、减少过拟合风险,并具有稀疏性和鲁棒性。与其他损失函数相比,铰链损失对分类边际要求更严格,计算更简单,优化更高效。
该函数的核心特性在于其凸性保证了全局最优解,非光滑性与支持向量概念密切相关,而稀疏性则提高了模型泛化能力,最终实现了边际最大化。
铰链损失的工作机制分为三种情况:完全正确分类(y·f(x) ≥ 1)时损失为0;在边际区域内分类(0 < y·f(x) < 1)时,损失随样本靠近决策边界线性增加;错误分类(y·f(x) ≤ 0)时,损失大于1,并随预测值偏离真实标签线性增加。
文章提供了Python代码实现,包括基础实现和向量化优化版本。铰链损失的优势在于最大化分类边际、提高泛化能力、减少过拟合风险,并具有稀疏性和鲁棒性。与其他损失函数相比,铰链损失对分类边际要求更严格,计算更简单,优化更高效。
怜星夜思:
1、除了文中提到的几种情况,大家觉得在实际应用中,有没有其他因素会影响铰链损失的效果?
2、文章提到了铰链损失的稀疏性,这个特性在实际应用中有什么好处呢?除了计算效率和存储需求,还能带来其他优势吗?
3、铰链损失函数与其他损失函数,例如交叉熵损失函数,在实际应用中该如何选择?有没有什么经验法则可以分享?
2、文章提到了铰链损失的稀疏性,这个特性在实际应用中有什么好处呢?除了计算效率和存储需求,还能带来其他优势吗?
3、铰链损失函数与其他损失函数,例如交叉熵损失函数,在实际应用中该如何选择?有没有什么经验法则可以分享?
原文内容

本文约1500字,建议阅读5分钟
本文深入剖析了SVM核心机制。
铰链损失(Hinge Loss)是支持向量机(Support Vector Machine, SVM)中最为核心的损失函数之一。该损失函数不仅在SVM中发挥着关键作用,也被广泛应用于其他机器学习模型的训练过程中。从数学角度来看,铰链损失函数提供了一种优雅的方式来量化分类器的预测性能。
数学表达式
铰链损失函数的标准数学形式为:
L(y, f(x)) = max(0, 1 - y·f(x))
其中:
-
y ∈ {-1, 1}:表示真实标签
-
f(x):表示模型的预测输出
-
y·f(x):表示预测值与真实标签的乘积
核心特性
铰链损失函数具有以下关键特性:
-
凸性:函数在整个定义域上都是凸函数,这保证了优化过程能够收敛到全局最优解
-
非光滑性:在点y·f(x) = 1处不可导,这一特性与支持向量的概念密切相关
-
稀疏性:能够产生稀疏的支持向量,提高模型的泛化能力
-
边际最大化:通过惩罚机制促进决策边界的边际最大化
工作机制详解
铰链损失函数的工作机制可以分为三种情况:
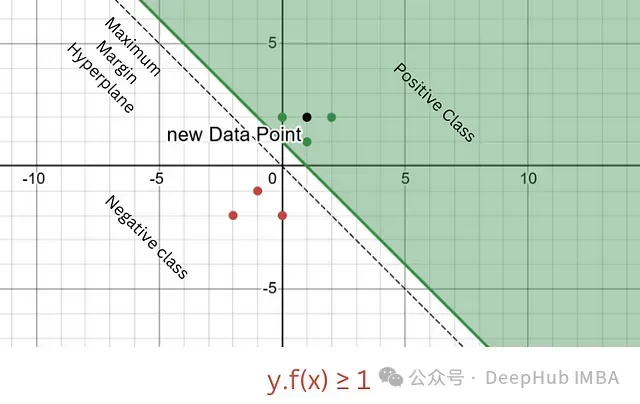
完全正确分类 (y·f(x) ≥ 1)
在这种情况下:
-
样本被正确分类,且位于分类边际之外
-
损失值为0
-
数学表达:max(0, 1 - y·f(x)) = 0

示例计算:当y·f(x) = 1.2时max(0, 1 - 1.2) = max(0, -0.2) = 0
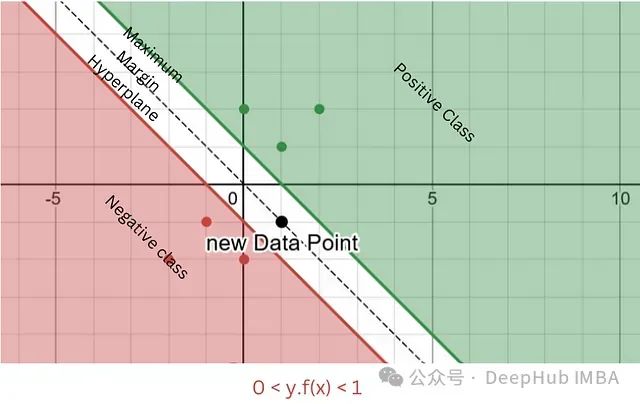
边际区域内的分类 (0 < y·f(x) < 1)
这种情况表示:
-
样本分类正确,但落在分类边际内
-
损失值随着样本向决策边界靠近而线性增加
-
通过这种机制鼓励模型建立更宽的分类边际
示例计算:当y·f(x) = 0.5时max(0, 1 - 0.5) = 0.5
错误分类 (y·f(x) ≤ 0)
在这种情况下:
-
样本被错误分类
-
损失值大于1,且随着预测值偏离真实标签而线性增加
-
这提供了强烈的梯度信号,促使模型调整参数
示例计算:当y·f(x) = -0.4时max(0, 1 - (-0.4)) = max(0, 1.4) = 1.4
实现与优化
基础实现
以下是铰链损失函数的基础Python实现:
import numpy as np
def hinge_loss(y_true, y_pred):
“”"
计算铰链损失参数:
y_true: 真实标签,取值为{-1, 1}
y_pred: 模型预测值返回:
每个样本的铰链损失值
“”"
return np.maximum(0, 1 - y_true * y_pred)示例使用
y_true = np.array([1, -1, 1])
y_pred = np.array([0.8, -0.5, -1.2])
loss = hinge_loss(y_true, y_pred)
print(“Hinge Loss:”, loss)
向量化实现与优化
在实际应用中,我们通常需要更高效的实现方式:
def vectorized_hinge_loss(y_true, y_pred, average=True): """ 向量化的铰链损失计算参数:
y_true: 真实标签数组,形状为(n_samples,)
y_pred: 预测值数组,形状为(n_samples,)
average: 是否返回平均损失
返回:
损失值或损失数组
“”"
losses = np.maximum(0, 1 - y_true * y_pred)
return np.mean(losses) if average else losses
实际应用中的考虑因素
优势
边际最大化
-
自动寻找最优分类边际
-
提高模型的泛化能力
-
减少过拟合风险
稀疏性
-
产生稀疏的支持向量
-
提高模型的计算效率
-
降低存储需求
鲁棒性
-
对异常值不敏感
-
具有良好的泛化性能
-
适合处理线性可分问题
与其他损失函数的比较
相对于对数损失
-
铰链损失对分类边际的要求更严格
-
不要求概率输出
-
计算更简单,优化更高效
相对于0-1损失
-
提供了连续的梯度信息
-
便于优化
-
对模型的鲁棒性要求更高
总结
铰链损失函数是支持向量机中的核心组件,它通过优雅的数学形式实现了以下目标:
-
最大化分类边际
-
提供有效的优化目标
-
产生稀疏的解
在实际应用中,深入理解铰链损失的特性和实现细节,对于构建高效且鲁棒的分类模型至关重要。
