阿里开源万相2.1视觉生成模型,性能超越Sora,支持文/图生视频,消费级显卡即可运行。
原文标题:超越Sora!阿里万相大模型正式开源,消费级显卡也能跑!
原文作者:AI前线
冷月清谈:
万相2.1在VBench评测中以86.22%的总分超越Sora、Luma、Pika等模型,位居榜首。其1.3B版本性能也超过了其他更大尺寸的开源模型,甚至接近一些闭源模型,且仅需8.2GB显存即可运行,方便二次开发和学术研究。
该模型采用DiT架构和线性噪声轨迹Flow Matching范式,并研发了高效的因果3D VAE和可扩展的预训练策略。其因果3D VAE中的特征缓存机制支持任意长度视频的编解码,并通过空间降采样压缩减少了内存占用。
在各项测试中,万相在运动质量、视觉质量、风格和多目标等方面均表现出色,尤其在复杂运动和物理规律遵循上大幅提升。
阿里云自2023年起坚持大模型开源路线,千问模型衍生模型已超过10万个。万相的开源进一步完善了阿里云全模态、全尺寸大模型的开源布局。
怜星夜思:
2、万相模型与其他开源视频生成模型相比,有哪些独特的优势?除了性能指标上的提升,还有什么其他方面的改进?
3、阿里开源万相模型的举动,对国内AI视频生成领域的发展会产生哪些影响?
原文内容

2 月 25 日消息,阿里云旗下视觉生成基座模型万相 2.1(Wan)重磅开源,此次开源采用最宽松的 Apache2.0 协议,14B 和 1.3B 两个参数规格的全部推理代码和权重全部开源,同时支持文生视频和图生视频任务,全球开发者可在 Github、HuggingFace 和魔搭社区下载体验。
开源地址:
Github: https://github.com/Wan-Video
HuggingFace: https://huggingface.co/Wan-AI
魔搭社区:https://modelscope.cn/organization/Wan-AI
据介绍,14B 万相模型在指令遵循、复杂运动生成、物理建模、文字视频生成等方面表现突出,在权威评测集 VBench 中,万相 2.1 以总分 86.22% 的成绩大幅超越 Sora、Luma、Pika 等国内外模型,稳居榜首位置。1.3B 版本测试结果不仅超过了更大尺寸的开源模型,甚至还接近部分闭源模型,同时能在消费级显卡运行,仅需 8.2GB 显存就可以生成高质量视频,适用于二次模型开发和学术研究。
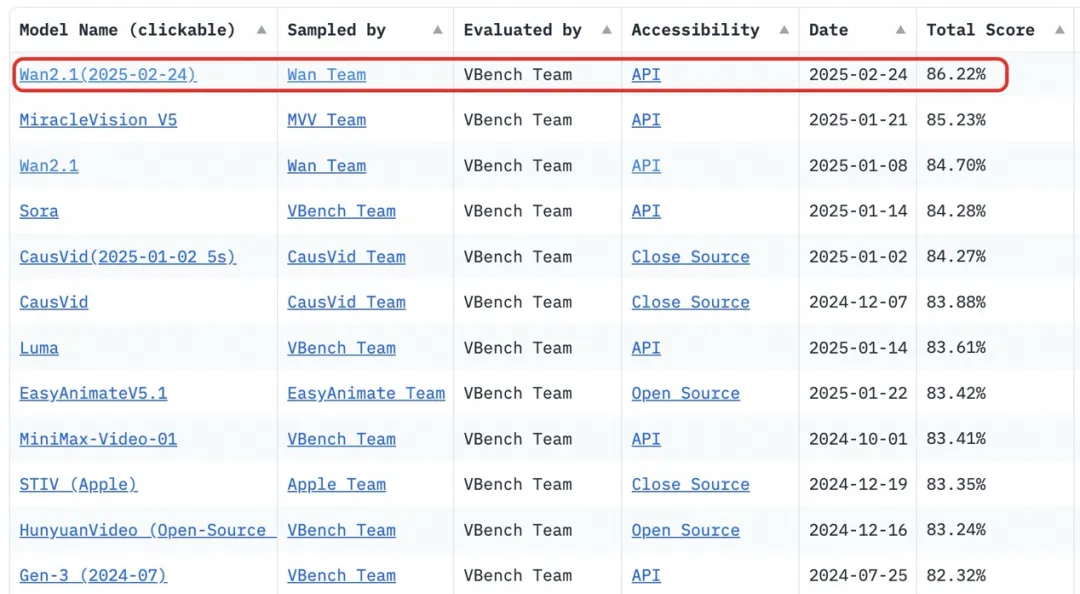
(万相 2.1 以总分 86.22% 的成绩稳居 VBench 榜单第一)
在算法设计上,万相基于主流 DiT 架构和线性噪声轨迹 Flow Matching 范式,研发了高效的因果 3D VAE、可扩展的预训练策略等。以 3D VAE 为例,为了高效支持任意长度视频的编码和解码,万相在 3D VAE 的因果卷积模块中实现了特征缓存机制,从而代替直接对长视频端到端的编解码过程,实现了无限长 1080P 视频的高效编解码。此外,通过将空间降采样压缩提前,在不损失性能的情况下进一步减少了 29% 的推理时内存占用。
万相团队的实验结果显示,在运动质量、视觉质量、风格和多目标等 14 个主要维度和 26 个子维度测试中,万相均达到了业界领先表现,并且斩获 5 项第一。尤其在复杂运动和物理规律遵循上的表现上大幅提升,万相能够稳定展现各种复杂的人物肢体运动,如旋转、跳跃、转身、翻滚等;能够精准还原碰撞、反弹、切割等复杂真实物理场景。
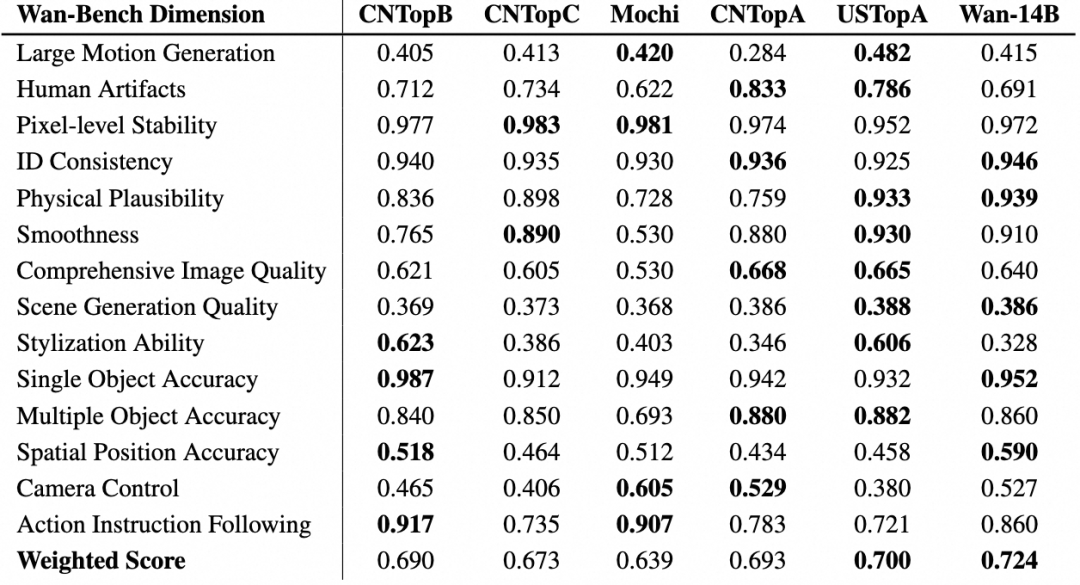
(万相在 14 个主要维度测试中斩获 5 项第一及平均分第一)
从 2023 年开始,阿里云就坚定大模型开源路线,其千问(Qwen)衍生模型数量已超过 10 万个,是全球最大的 AI 模型家族。随着万相的开源,阿里云实现了全模态、全尺寸大模型的开源。
下面我们可以看下万相 2.1 的实际生成效果。
输入 Prompt:
体育摄影风格,骑手在场地障碍赛中引导马匹快速通过障碍物。骑手身着专业比赛服,头戴安全帽,表情专注而坚定,双手紧握缰绳,双腿夹紧马腹,与马匹完美配合。马匹腾空跃起,动作连贯且准确,四蹄有力地踏过每一个障碍物,保持速度和平衡。背景是自然的草地和蓝天,画面充满动感和紧张感。4K, 高清画质, 动作完整。
生成图片:

输入 Prompt:
体育摄影风格,中国皮划艇运动员在激流回旋比赛中,于湍急的水流中用桨快速划水,灵活地绕过一个又一个障碍物。他身着专业运动服,肌肉线条明显,表情专注而坚定,展现出出色的操控技术和顽强的拼搏精神。背景是清澈的河流和翠绿的山峦,画面充满动感与活力。近景特写,运动员在空中翻转滑板,动作完整,4K, 高清画质。
生成图片:

输入 Prompt:
一段超速 POV 镜头,摄像机疾驰穿越一条阳光下的中国乡村小路,镜头紧跟着一个在空中飞行的穿着休闲服休闲鞋的中国女子的背后,她身体直立展开双臂,风吹动她的头发和衣服。
生成图片:

在 AI 大模型重塑软件开发的时代,我们如何把握变革?如何突破技术边界?4 月 10-12 日,QCon 全球软件开发大会· 北京站 邀你共赴 3 天沉浸式学习,跳出「技术茧房」,探索前沿科技的无限可能。
本次大会将汇聚顶尖技术专家、创新实践者,共同探讨多行业 AI 落地应用,分享一手实践经验,深度参与 DeepSeek 主题圆桌,洞见未来趋势。

