清华北大联合发布FreEformer模型,利用频域Transformer提升多元时序预测效果,解决注意力矩阵低秩问题。
原文标题:清华&北大联合发布:频域多元时序预测Transformer模型
原文作者:数据派THU
冷月清谈:
清华大学和北京大学的研究人员最近联合发布了一种新的时间序列预测模型——FreEformer,该模型的核心在于利用频域Transformer进行建模。
与传统时域模型相比,频域模型能够更好地捕捉时间序列的全局信息,例如不同时间片段的频域表征具有一致性,以及不同变量之间的相关性在频域中更为显著。
FreEformer模型首先对原始时间序列进行归一化和维度扩展,然后使用离散傅里叶变换将其转换到频域。转换后的实部和虚部分别输入到两个独立的多层Transformer模型中进行处理。处理后的输出再经过线性变换和逆向离散傅里叶变换转换回时域,最终得到预测结果。
研究人员发现,在频域中使用Transformer时,生成的注意力矩阵存在低秩问题,这意味着提取的特征信息存在冗余。为了解决这个问题,他们对注意力机制进行了改进,在QK内积和softmax操作之后添加了一个可学习的矩阵B。这种改进相当于将注意力机制和MLP进行了融合,能够有效提升注意力矩阵的秩,从而提高特征多样性。
实验结果表明,FreEformer在长短周期的时间序列预测任务中均取得了显著的效果。
与传统时域模型相比,频域模型能够更好地捕捉时间序列的全局信息,例如不同时间片段的频域表征具有一致性,以及不同变量之间的相关性在频域中更为显著。
FreEformer模型首先对原始时间序列进行归一化和维度扩展,然后使用离散傅里叶变换将其转换到频域。转换后的实部和虚部分别输入到两个独立的多层Transformer模型中进行处理。处理后的输出再经过线性变换和逆向离散傅里叶变换转换回时域,最终得到预测结果。
研究人员发现,在频域中使用Transformer时,生成的注意力矩阵存在低秩问题,这意味着提取的特征信息存在冗余。为了解决这个问题,他们对注意力机制进行了改进,在QK内积和softmax操作之后添加了一个可学习的矩阵B。这种改进相当于将注意力机制和MLP进行了融合,能够有效提升注意力矩阵的秩,从而提高特征多样性。
实验结果表明,FreEformer在长短周期的时间序列预测任务中均取得了显著的效果。
怜星夜思:
1、FreEformer 模型中提到的频域信息在时间序列预测中有什么优势?除了文中提到的全局信息和变量相关性之外,还有其他优势吗?
2、文章中提到Transformer在频域建模的attention矩阵具有低秩性,导致特征多样性较差。除了文中提出的方法,还有什么其他方法可以解决这个问题?
3、FreEformer 模型主要应用于哪些场景?相比于其他时序预测模型,它有哪些局限性?
2、文章中提到Transformer在频域建模的attention矩阵具有低秩性,导致特征多样性较差。除了文中提出的方法,还有什么其他方法可以解决这个问题?
3、FreEformer 模型主要应用于哪些场景?相比于其他时序预测模型,它有哪些局限性?
原文内容

来源:圆圆的算法笔记本文约1000字,建议阅读5分钟
本文提出了一种基于频域Transformer的时间序列预测模型,并通过改造attention计算逻辑提升频域特征多样性。
今天给大家介绍的这篇文章是清华大学、北京大学联合发表的一篇时间序列预测工作,提出了一种基于频域Transformer的时间序列预测模型,并通过改造attention计算逻辑提升频域特征多样性。

论文标题:FreEformer: Frequency Enhanced Transformer for Multivariate Time Series Forecasting
下载地址:https://arxiv.org/pdf/2501.13989v1
1 研究背景
频域信息应用到时间序列预测已经有很多相关的研究工作,频域信息的主要优势在于其相比于时域,提取了一种时间序列的全局信息。比如下图中,一个时间序列不同的片段它们在频域的表征具有一致性,第二行和第三行对应一个时间序列两个不同的变量,在频域也更能体现其相关性。

因此,本文直接使用Transformer在频域进行建模。同时,在研究过程中发现Transformer在频域建模的attention矩阵具有低秩性,文中也通过对attention模块进行改造解决。
2 建模方法
本文的模型整体结构如下图所示。对于原始的时间序列,使用ReVIN进行归一化后,每个时间步的数值过一个MLP扩展维度,作为后续模型的输入。接下来,使用离散傅里叶变换映射到频域,将映射后的表征的实数部分和虚数部分分别过2个多层Transformer模型(文中实验对比发现这种独立建模的方法效果最好)。实部和虚部的Transformer输出接一个Linear后再过逆向离散傅里叶变换映射回时域,相加得到最终的预测结果。
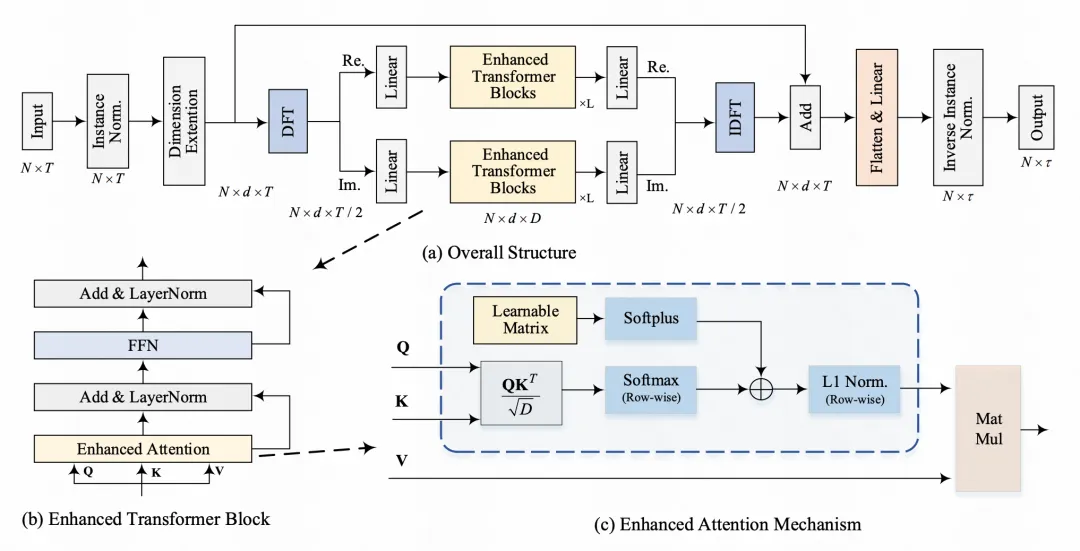
文中研究发现,频域的Transformer生成的attention矩阵存在低秩性。矩阵的秩指的是其中不相关向量的个数,如果一个矩阵的秩很低,就有很多向量是平行的,所提取的特征信息也是冗余的。比如下图对比了频域基础Transformer和其他时域Transformer的秩,可以看到明显偏低,特征多样性较差。

为了解决该问题,本文将attention的计算改为如下形式,QK内积+softmax后,增加了一个可学习的矩阵B,B是数据集维度的:

这其实是一种attention和MLP的融合,如果将前面QK内积部分去掉,模型就退化成了一个MLP模型。文中通过理论验证这种方法可以提升最终矩阵的秩,进而提升特征多样性。引入这个改造后,从下图可以看出attention矩阵的秩明显提升了。

3 实验效果
在长短周期的时间序列预测任务中,本文提出的方法都取得了不错的效果。

编辑:文婧
