DeepSeek开源DualPipe、EPLB及性能分析数据,提升大模型训练推理效率。
原文标题:DeepSeek一口气开源3个项目,还有梁文锋亲自参与,昨晚API大降价
原文作者:机器之心
冷月清谈:
DeepSeek开源了DualPipe、EPLB以及训练和推理框架的分析数据。DualPipe是一种双向pipeline并行算法,用于计算-通信重叠,减少流水线气泡,提高训练效率。它通过让不同部分并行工作来消除低效,类似于交响乐团中不同乐器组同时演奏。EPLB则是一个专家-并行负载均衡器,用于解决专家并行中的负载不均衡问题,通过智能分配专家来最大化GPU利用率并最小化通信开销。DeepSeek还公布了训练和推理框架的分析数据,帮助社区更好地理解通信-计算重叠策略和底层实现细节。这些数据可以使用PyTorch Profiler捕获,并通过Chrome或Edge浏览器的tracing功能进行可视化。
怜星夜思:
1、DualPipe 的这种优化策略,相比于传统的流水线并行,除了效率提升之外,还有什么其他优势?例如在资源消耗、稳定性等方面?
2、EPLB的负载均衡策略是如何实现的?有没有一些更具体的技术细节可以了解?文章中提到的“启发式方法”具体指什么?
3、DeepSeek 开源这些工具和数据,除了对使用 DeepSeek 模型的用户有帮助外,对其他大模型的训练和推理有什么借鉴意义?
2、EPLB的负载均衡策略是如何实现的?有没有一些更具体的技术细节可以了解?文章中提到的“启发式方法”具体指什么?
3、DeepSeek 开源这些工具和数据,除了对使用 DeepSeek 模型的用户有帮助外,对其他大模型的训练和推理有什么借鉴意义?
原文内容
机器之心报道
编辑:张倩、泽南
实现顶级 AI 性能的秘诀,就在这里了。
DeepSeek 的开源周已经进行到了第四天(前三天报道见文末「相关阅读」)。今天这家公司一口气发布了两个工具和一个数据集:DualPipe、EPLB 以及来自训练和推理框架的分析数据。
DeepSeek 表示,DualPipe 曾在 V3/R1 的训练中使用,是一种用于计算 - 通信重叠的双向 pipeline 并行算法。
EPLB 是为 V3/R1 打造的专家 - 并行负载均衡器。
而公布训练和推理框架的分析数据是为了帮助社区更好地理解通信 - 计算重叠策略和底层实现细节。

-
DualPipe 链接:https://github.com/deepseek-ai/DualPipe
-
EPLB 链接:https://github.com/deepseek-ai/eplb
-
计算分析链接:https://github.com/deepseek-ai/profile-data
值得一提的是,在 DualPipe 的 GitHub 上,DeepSeek 创始人梁文锋位列开发者行列之中。

技术语言可能不好理解,我们来看一下网友给出的比喻:
想象一下,训练一个庞大的语言模型就像指挥一个交响乐团。每个 GPU 就像一位音乐家,执行其分配的计算任务,而训练框架则充当指挥,保持一切完美同步。在典型设置中,音乐家们可能需要等待彼此,造成尴尬的停顿。这些延迟,被称为流水线气泡,会减慢整个过程。
DualPipe 通过允许不同部分并行工作来消除这些低效,就像弦乐部演奏的同时铜管部也在排练。这种努力的重叠确保没有停机时间。
有网友评价说,「DualPipe 不仅仅是另一种流水线并行实现。它解决的根本问题是标准流水线并行中固有的低效率。传统方法如 1F1B(一次前向,一次后向)甚至 Zero Bubble(ZB1P)都存在流水线气泡 —— 即各计算单元等待数据时的空闲时间。DualPipe 旨在实现前向和后向计算 - 通信阶段的完全重叠,最大限度地减少了这些气泡。」

而关于 EPLB,我们可以这么理解:传统的数据并行就像给每个人一份整个项目的副本 —— 既浪费又缓慢。专家并行(EP),即每个专家驻留在不同的 GPU 上,如果可以平衡负载,则效率要高得多。EPLB 就是为了解决这种专家失衡问题而设计的。这不仅仅是分配专家;它是关于智能地分配它们,以最大限度地提高 GPU 利用率和最小化通信开销。

到现在为止,DeepSeek 似乎已经把发布 V3、R1 模型时未公布的很多训练、部署细节也公开了出来。人们不仅可以在此基础上更好地使用 DeepSeek 模型,在使用其他大模型时也能获得助益。
明天周五,是开源周的最后一天,DeepSeek 有可能用 R2 来收尾吗?
让我们先来看看今天开源的三个项目。
DualPipe
DualPipe 是在 DeepSeek-V3 技术报告中引入的一种创新的双向流水线并行算法。它实现了前向和后向计算 - 通信阶段的完全重叠,同时减少了流水线气泡。有关计算 - 通信重叠的详细信息,请参阅配置文件数据:https://github.com/deepseek-ai/profile-data
调度

DualPipe 调度示例:8 个 流水线并行(PP)级别和 20 个双向 micro-batch。反向的 micro-batch 与前向的 micro-batch 对称,因此图中省略了它们的 batch ID 。被共享的黑色边框包围的两个单元格具有相互重叠的计算和通信。
有网友制作了 DualPipe 与其他两种方法 ——1F1B and ZB1P 的对比图:
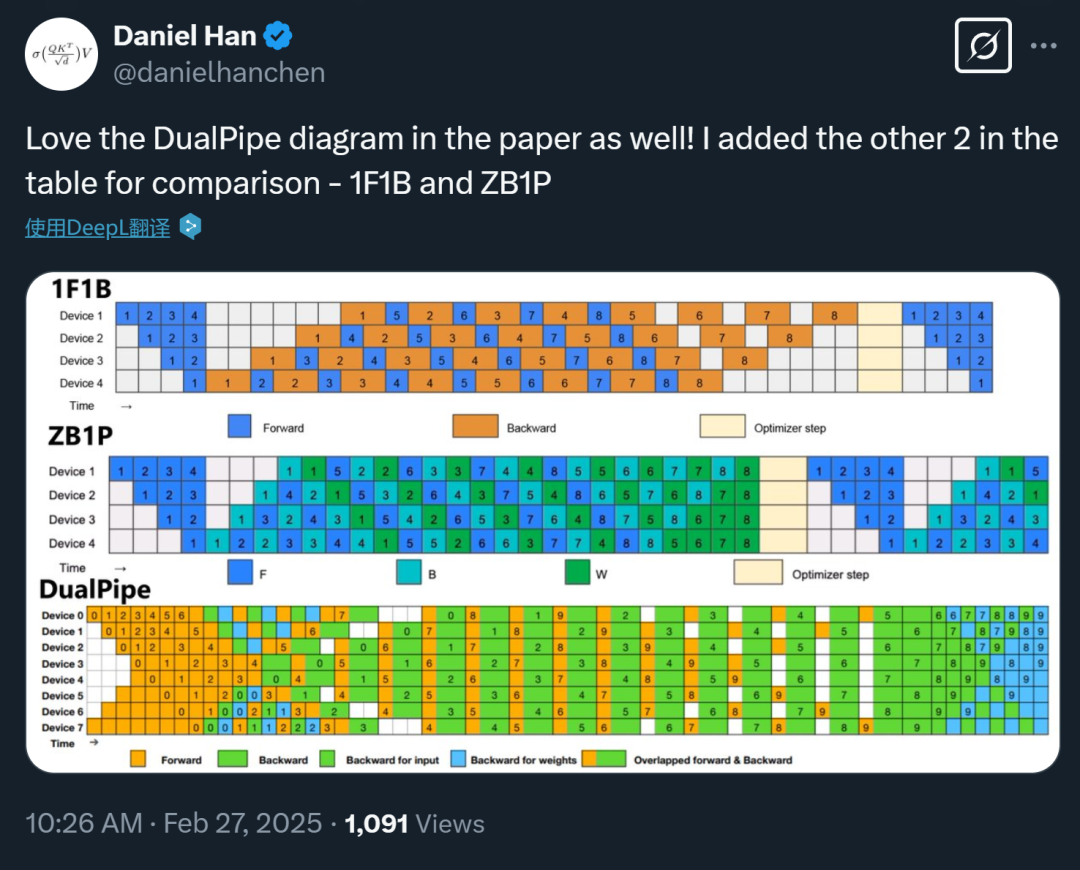
Pipeline 气泡和内存使用情况比较
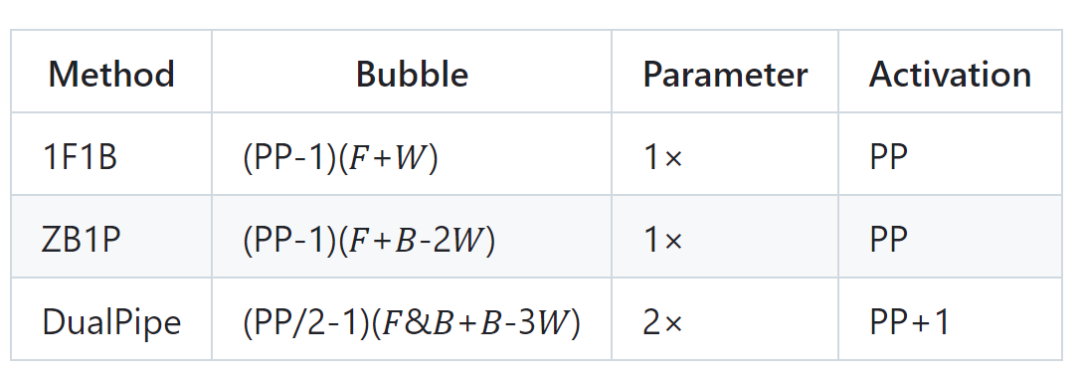
𝐹 表示前向数据块的执行时间,𝐵 表示完整后向数据块的执行时间,𝑊 表示「权重后向」数据块的执行时间,𝐹&𝐵 表示两个相互重叠的前向和后向数据块的执行时间。
DualPipe由Jiashi Li、Chengqi Deng、梁文锋创建和开发。更多信息请参见GitHub代码库。
EPLB
在使用专家并行(Expert Parallelism,EP)时,不同的专家被分配到不同的 GPU 上。由于不同专家的负载可能会根据当前工作负载而变化,保持不同 GPU 之间的负载平衡非常重要。正如 DeepSeek-V3 论文中所描述的,工程师们采用了冗余专家策略,复制高负载的专家。然后,DeepSeek 通过启发式方法将这些复制的专家打包到 GPU 上,以确保不同 GPU 之间的负载平衡。
此外,得益于 DeepSeek-V3 中使用的组限制专家路由(group-limited expert routing),DeepSeek 工程师还尽可能地将同一组的专家放置在同一节点上,以减少节点间的数据传输。
为了便于复现和部署,DeepSeek 在 eplb.py 中开源了部署的 EP 负载平衡算法。该算法根据估计的专家负载计算出一个平衡的专家复制和放置方案。请注意,预测专家负载的确切方法超出了本仓库的范围。一种常见的方法是使用历史统计数据的移动平均值。

DeepSeek Infra 中的数据分析
DeepSeek 公开分享了自身的训练和推理框架分析数据,以帮助社区更好地了解通信计算重叠策略和低级实现细节。该分析数据是使用 PyTorch Profiler 捕获的。下载后,人们可以通过在 Chrome 浏览器中导航到 chrome://tracing(或在 Edge 浏览器中导航到 edge://tracing)来直接对其进行可视化。

训练配置文件数据展示了 DeepSeek 在 DualPipe 中针对一对单独的前向和后向块的重叠策略。每个块包含 4 个 MoE(专家混合)层。并行配置与 DeepSeek-V3 预训练设置一致:EP64、TP1 具有 4K 序列长度。并且为简单起见,在分析过程中不包括 PP 通信。
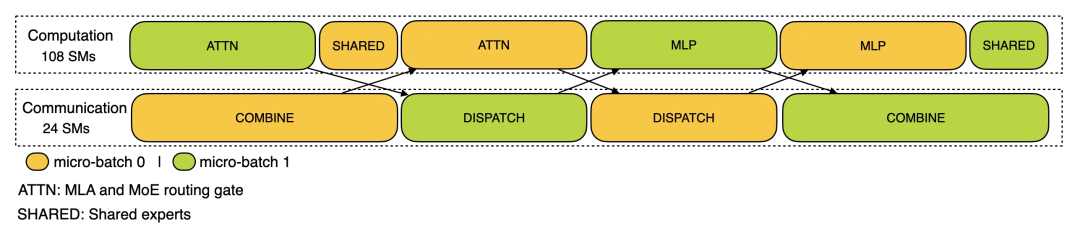
在推理上,对于预填充,该配置文件采用 EP32 和 TP1(与 DeepSeek V3/R1 的实际在线部署一致),提示长度设置为 4K,每 GPU 的批大小为 16K 个 token。在预填充阶段,DeepSeek 使用两个 micro-batch 来重叠计算和全对全通信,同时确保注意力计算负载在两个微批次之间保持平衡 —— 这意味着同一个提示可以在它们之间拆分。
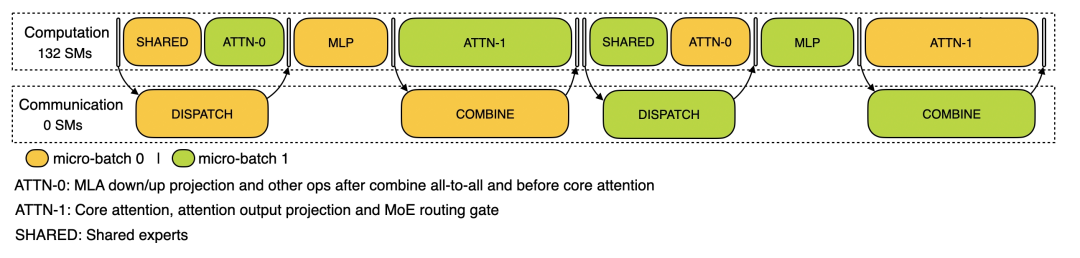
对于解码,该配置文件采用 EP128、TP1 和 4K 的提示长度(与实际的在线部署配置非常接近),每个 GPU 的批处理大小为 128 个请求。与预填充类似,解码也利用两个 micro-batch 进行重叠计算和全对全通信。但是,与预填充不同,解码期间的全对全通信不占用 GPU SM:发出 RDMA 消息后,所有 GPU SM 都被释放,系统等待计算完成后全对全通信完成。
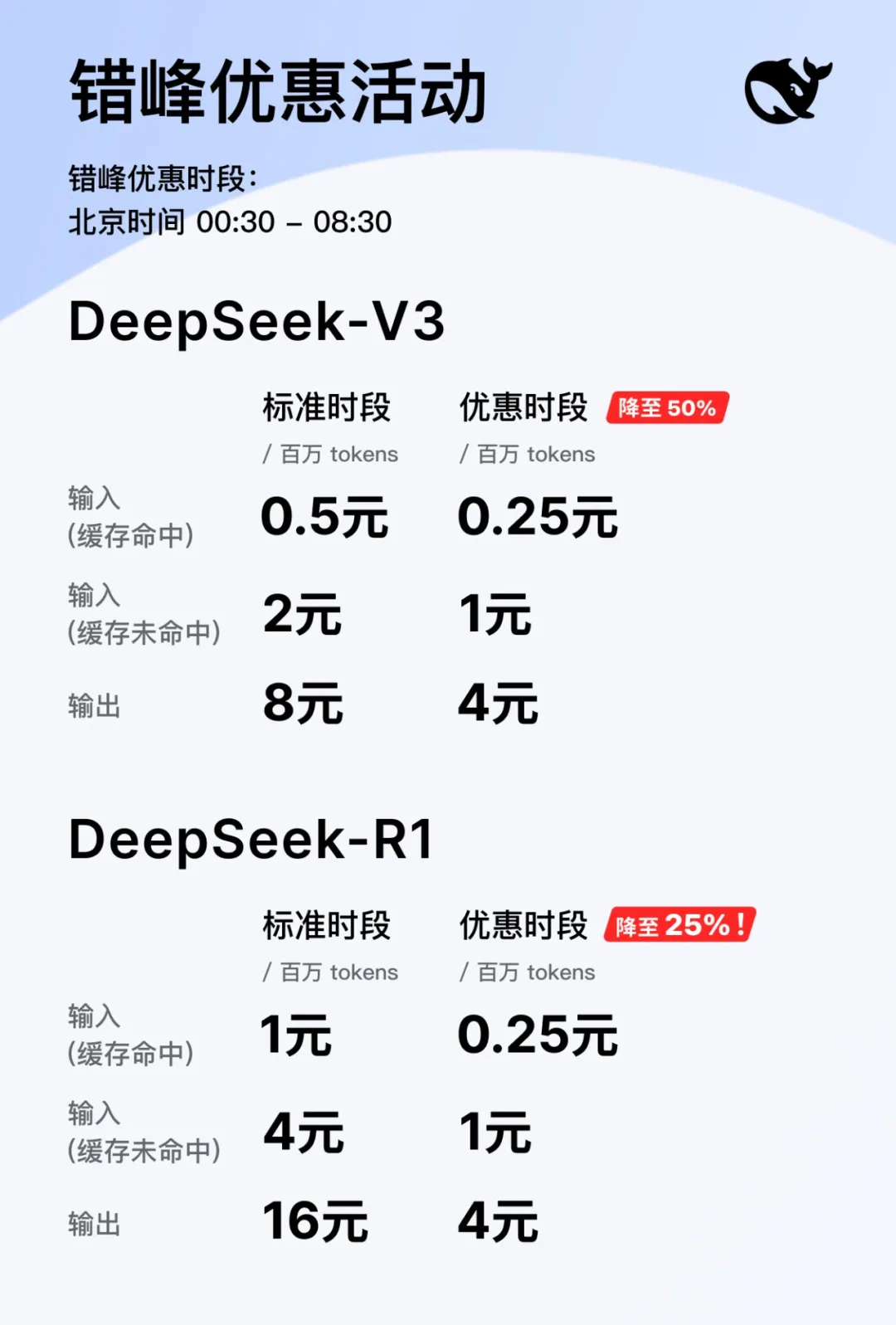
DeepSeek 错峰优惠,半夜跑 AI 更省钱
除了持续开源,DeepSeek 这两天还宣布了一些重要消息:一是恢复 API 开放平台充值;二是北京时间每日 00:30 至 08:30 的夜间空闲时段,推出错峰优惠活动。在此期间,API 调用价格大幅下调:DeepSeek-V3 降至原价的 50%,DeepSeek-R1 更低至 25%。这一使用方式被网友称为「峰谷 token」。
有人利用峰谷电特点半夜洗碗、烘衣服,自然也有人半夜跑 AI 任务。有用户表示,「一些批量的任务可以到晚上让它自动运行了」「DeepSeek 是懂年轻人的」。
而在大洋彼岸,需要 DeepSeek 的打工人正常时段就可以享受到优惠,美国打工人高呼「真香」。

所以,现在压力给到了其他 API 供应商,这波降价潮,其他家跟不跟?
相关阅读:
《》
《》
《》
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]