北大aiXcoder-7B代码大模型,融合深度学习和软件工程,提升代码理解和生成能力,已被ICSE 2025收录。
原文标题:如何训练最强代码大模型?北大aiXcoder-7B贡献前沿实践
原文作者:机器之心
冷月清谈:
aiXcoder-7B的创新之处在于:
1. 数据预处理:使用语法分析和静态分析工具预处理数据,去除语法错误、Bug和安全漏洞,提高代码质量。
2. 结构化FIM:基于抽象语法树结构构建训练任务,使模型理解代码结构。
3. 多文件排序:考虑内容相似性和依赖性关系对项目内代码文件排序,提升模型对多文件关系的建模能力。
这些改进使得aiXcoder-7B在代码补全任务中表现出色,能够生成更符合真实场景的代码,并对代码的上下文结构展现出更出色的感知能力。
怜星夜思:
2、文中提到的结构化FIM(SFIM)方法相比传统的FIM方法有什么优势?这种基于语法树的训练方式对代码大模型的发展有什么启示?
3、aiXcoder-7B 如何处理跨文件的代码上下文信息?这种处理方式对实际的代码补全任务有什么帮助?
原文内容
![]()
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]
本文的通讯作者是北京大学计算机学院长聘教授李戈。
本文一作是 aiXcoder 蒋思源和北大李戈教授课题组博士生李佳,团队重点关注融合深度学习与软件工程的代码建模方法。
如何训练一个代码大模型?这一过程看似简单:获取代码数据、清洗数据,最终启动训练。如今,开源代码数据集层出不穷;数据清洗工具也已成熟,包括开源的许可证识别工具、MinHash 算法、PII 识别模型等;而在分布式训练方面,像 Megatron-LM、DeepSpeed 等框架也大大降低了技术门槛。看似我们只差计算资源,就能训练出一个强大的代码大模型。
然而,训练模型的初衷,应该始终从实际开发场景出发。作为开发者,我们不仅需要了解定义的各种 API 接口,还需要从入口函数模拟程序的执行过程,追踪到每一行修改的代码。在复杂的项目中,任何小小的变动都可能影响整个系统的运转。
但现有的代码大模型并未充分考虑到软件开发的具体场景,它们往往将最终版本的代码简单地视作自然语言文本,试图通过复制自然语言处理的成功经验来处理代码。这种方法忽略了代码的结构性和复杂的上下文关系,导致模型在实际开发中表现不佳。
北京大学 aiXcoder 团队一直致力于探索如何将深度学习与软件开发深度融合,推动软件开发的自动化。2024 年 4 月,aiXcoder 开源了自研代码大模型 aiXcoder-7B,成为这一领域的一次重要尝试,旨在将代码的抽象语法树(AST)结构与大规模预训练结合,以期提升模型对代码结构和上下文的理解能力。
近期,该篇论文被软件工程领域国际顶级会议 ICSE 2025 收录,将于 4 月 27 日 - 5 月 3 日赴加拿大渥太华参会分享研究成果。
此次论文录用不仅是对 aiXcoder 7B 代码大模型技术前瞻性和应用创新性的高度认可,更标志着该模型继成功落地企业并获各行业客户广泛认可后,再次于学术界获得权威肯定,充分彰显了 aiXcoder 在推动软件工程发展中的前瞻性引领作用。

-
论文地址:https://arxiv.org/pdf/2410.13187
-
开源项目地址:https://github.com/aixcoder-plugin/aiXcoder-7B
代码数据,异于自然语言
相较于自然语言文本,程序是现实世界解决方案在计算机系统中的映射。因此,程序源代码呈现出很多独特的性质,例如:强结构性、可执行性等等。有效地表示和建模这些特性,对于代码生成等任务来说至关重要。
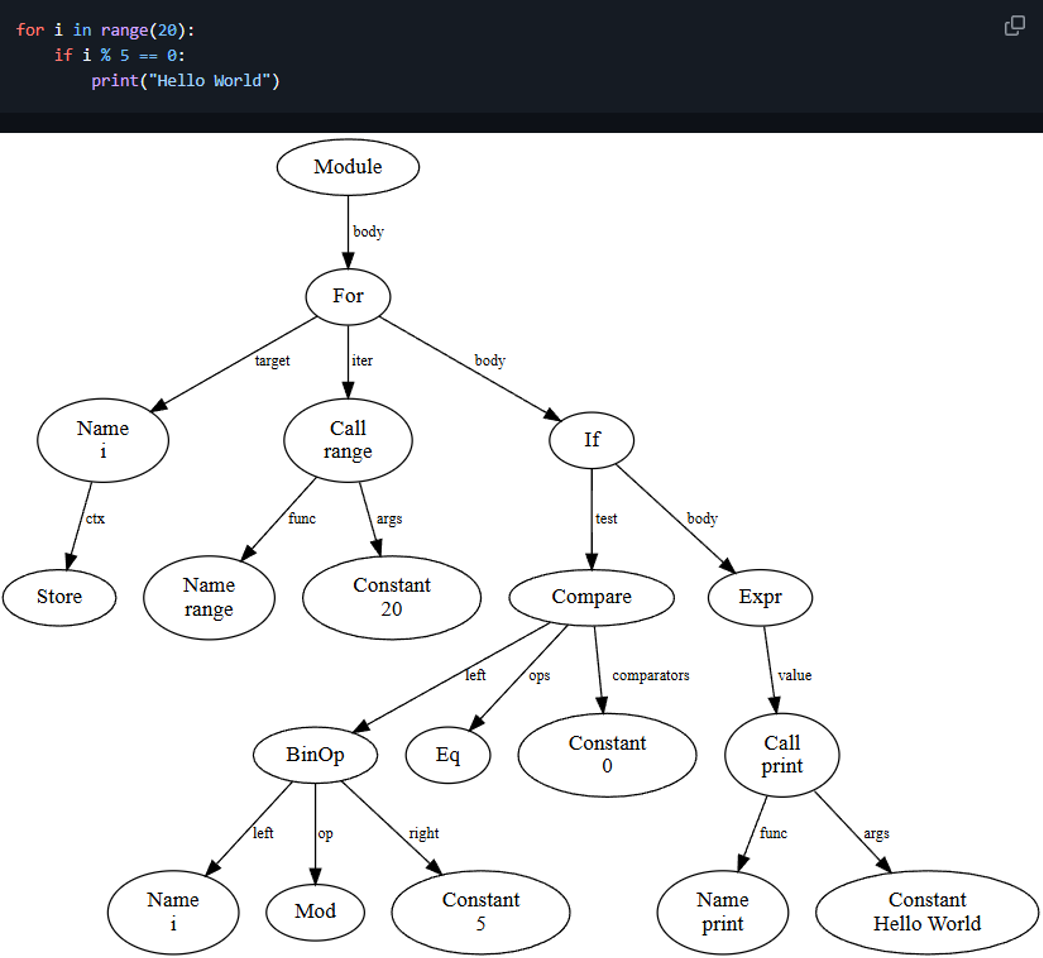
如上三行代码能够严格解析为抽象语法树格式
代码天然能被解析为抽象语法树,其语法规则严格组织了代码语句之间的关系。在语法规则之上,也有很多方式描述代码之间的流转关系,例如控制流图、调用流图等等。顾名思义,控制流图会展示整个代码控制与条件关系,什么样的条件下哪个分支代码会运行。调用流图则展示的是代码之间的调用关系,实现一个功能时在什么样的地方调用什么样的代码模块是能展示出来的。
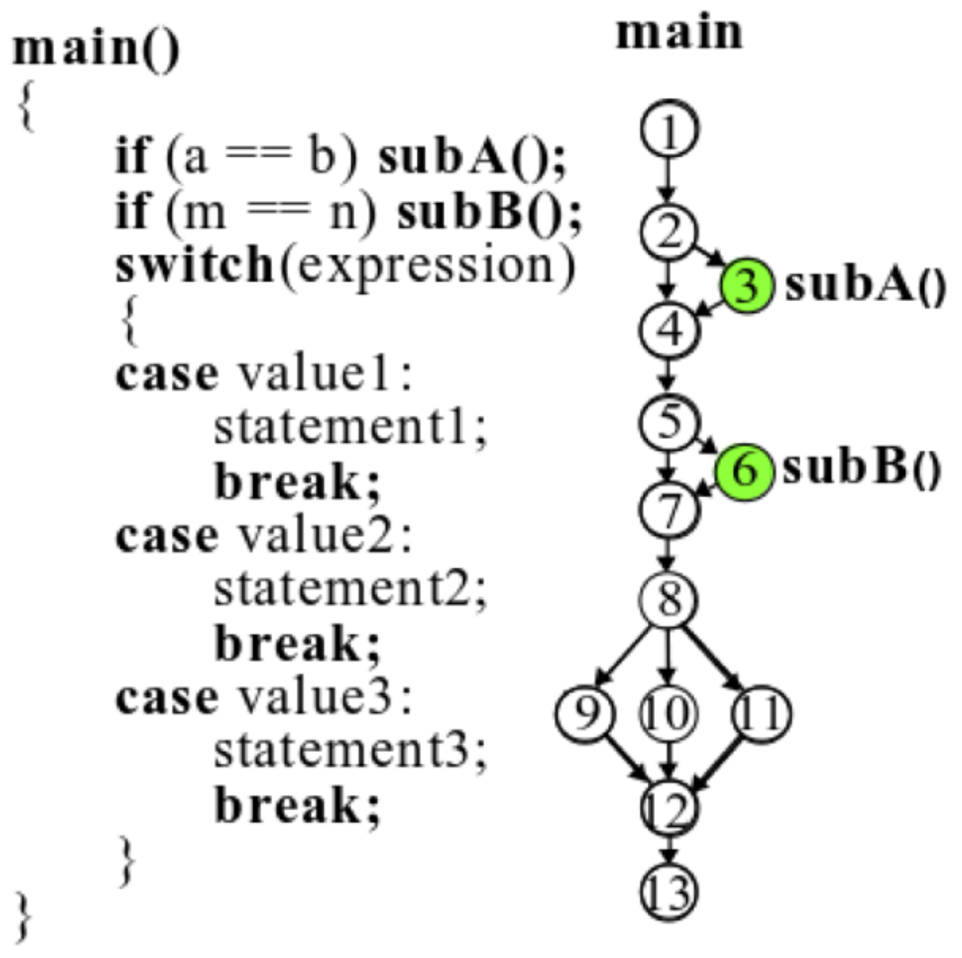
控制流图示例,代码执行条件与顺序会解析成流程图。
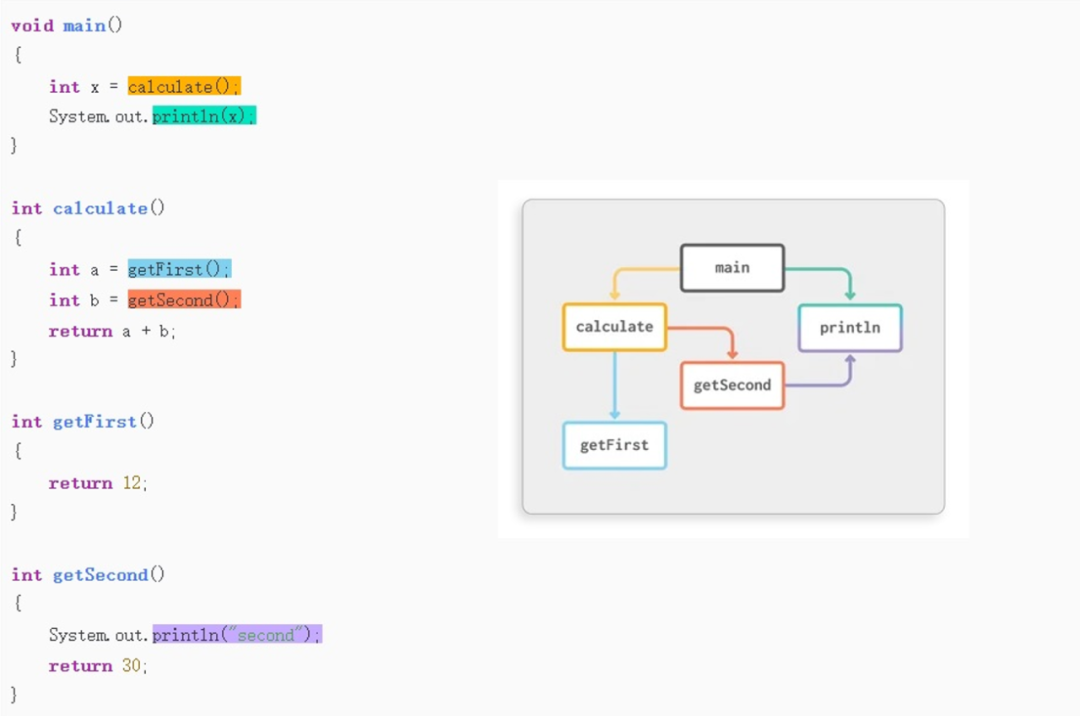
调用流图示例,main 函数调用 calculate 函数计算两个数之和,calculate 函数调用另外两个函数 getFirst 和 getSecond 获取参与计算的两个加数。
程序语言与自然语言之间存在显著差异。尽管大模型通过大规模自回归训练任务在通用知识学习上取得了巨大成功,但这并不意味着可以简单地将代码数据视为「自然语言」,并将其拉长为一维 Token 序列进行自回归训练,就能复制自然语言处理的成功。
事实上,当使用自回归模型或「Fill in the middle」任务训练基础模型时,会发现实际在代码补全任务中,模型生成的结果往往与人类程序员的编程方式不符,我们还需要更符合代码的预训练方法。
aiXcoder-7B:创新在 LLM 上引入代码特性
正因为当前代码大模型很少将代码特性引入到 LLM 的训练过程中,代码大模型在企业真实项目中表现得不尽人意,所以我们创新将一些传统软件工程方法引入到大规模预训练中,希望能生成更符合真实场景的代码内容。
为此,aiXcoder-7B 主要从以下几个方面优化预训练:
-
数据预处理:软工工具保证代码数据语法正确且不存在严重 Bug
-
结构化 FIM:按照语法结构组织预训练任务
-
多文件排序:保证单项目内,文件排序既考虑内容相似,又考虑调用关系
数据预处理
aiXcoder 核心数据集主要用于强化代码大模型在以上编程语言上的效果,其经过大量的过滤与筛选过程。相比于其它代码大模型,aiXcoder-7B 预训练数据既采用常规的数据处理,例如数据去重、自动生成代码去除、通过 Star 量、正则等规则去除低质量代码、敏感信息等,同时借助软件工程方法进行更精细的数据处理。

具体而言,aiXcoder-7B 预训练数据采用语法分析和静态分析两大类工具预处理数据。对于语法分析,重点解析五十种主流语言的语法结构,并排除存在语法错误、简单 Bug 、大面积被注释掉的代码等。

语法分析能天然解析并处理明显不合理的代码
对于静态分析,则侧重解析十余种最主流编程语言的严重错误,即当出现这一些类型错误时,代码大概率在执行过程中会出现比较大的问题。具体而言,扫描并定位影响代码可靠性和可维护性的 161 种 Bug,影响代码安全性的 197 种安全漏洞。

静态分析能检测出很多更深层缺陷与漏洞的代码。
结合软件工程分析方法以及过滤规则,能够将存在明显问题的代码删除掉,明显提升整体代码质量。
结构化 FIM
在实际开发过程中,代码具有类、方法、条件代码块、循环代码块等众多结构。研究团队期待让代码大模型天然能学会这样的结构,而不是放任代码大模型向下一直生成,或者从字符层面上截取一个片段,期待补全该字符片段。
为此,团队结合语法分析方法,将代码解析为抽象语法树,并基于语法树的结构构建训练任务。具体而言,代码文件中的每个位置都对应着抽象语法树中的某个节点。在训练过程中,团队挖掉该节点的子节点,或者挖掉该节点所在父节点剩余的部分,然后针对被挖掉的代码块做一个先验约束:挖掉的代码块横跨一个或少数几个完整的代码结构。将这部分完整代码结构用来计算损失训练模型,就能一定程度上让代码模型理解部分语法结构。
更形象地解释,常规的 Fill in the middle 会构造很多不合法的代码片段,例如下图「or i in range (2」,常规的做法只是从字符上随机取一个片段。但论文研究团队提出的 Structured Fill-In-the-Middle (SFIM) 会随机先选定一个语法节点「IF」,并在 IF 节点向下取了「Compare」代码片段「i % 5 == 0:」
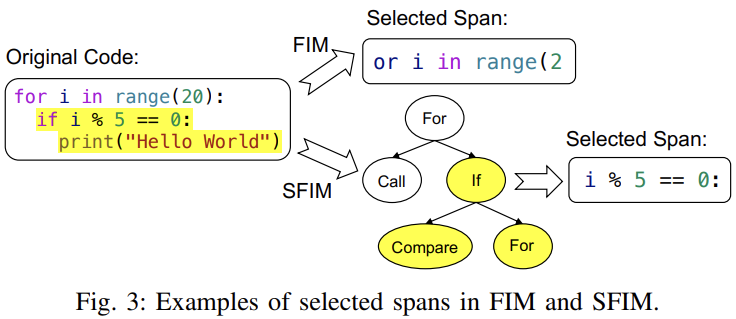
最终团队在预训练中根据 SFIM 构建整体训练损失计算,以此更好地学习代码的语法结构信息。
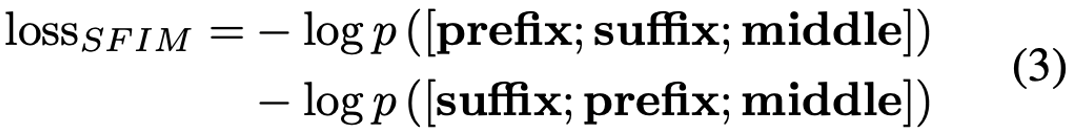
多文件排序
当前主流的代码开源数据集,例如 TheStackV1 、 TheStackV2 或者 The Pile 中代码部分,都是根据单个语言,甚至单一后缀名组织数据,致使整个训练样本的构造局限在单语言文件中。而此次研究团队构建的训练数据以项目为单位,保留与处理多种编程语言的代码文件,确保训练数据中编程语言的分布与真实开发一致。
此时有一个重要的问题:项目内不同文件该如何排序?
为了提升模型对项目内多代码文件关系的充分建模能力,并在推理过程中更高效地抽取有用的上下文信息,研究团队通过相似性关系和依赖性关系对代码文件排序:相似性关系即模型在预训练中能学会仿写相似的代码;依赖性关系即模型在预训练中能学会 API 调用或者函数调用的关系。

预训练中,项目内文件排序算法
如 Algorithm 1 所示,本论文给出了一个项目内文件排序伪代码。简单理解,以 0.3 的概率采用文件内容相似排序,即通过 KMeans 聚类算法将文件聚成不同的簇,并且同一个簇排列在一起;此外,以 0.3 的概率进行路径相似排序,把同一目录下的文件,或者被测代码与测试代码等路径相关的文件能排列在一起;最后还以 0.3 的概率构建函数调用流图,并根据图的叶节点一路向根节点建立程序依赖路径,将路径上的代码文件排列在一起。
aiXcoder 7B 独特的效果优势
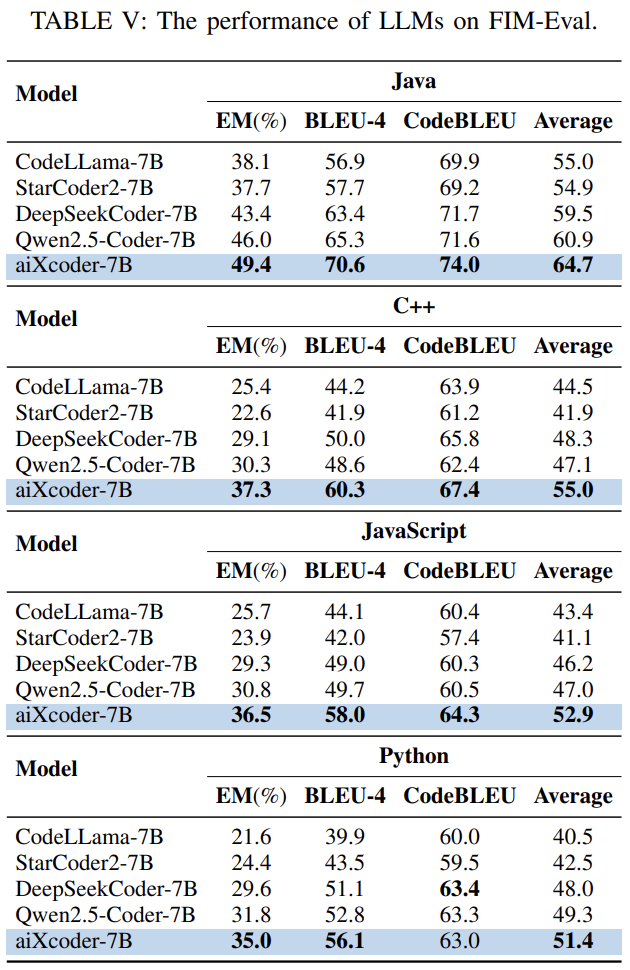
借助软件工程方法,研究团队通过更符合代码大模型的预训练方法,提升了其在代码数据上的理解与生成能力。例如论文表 5 中的 Fill-in-the-middle 评测集显示,经过高质量代码数据的 SFIM 任务训练,不同语言的代码补全能力有明显的提升。
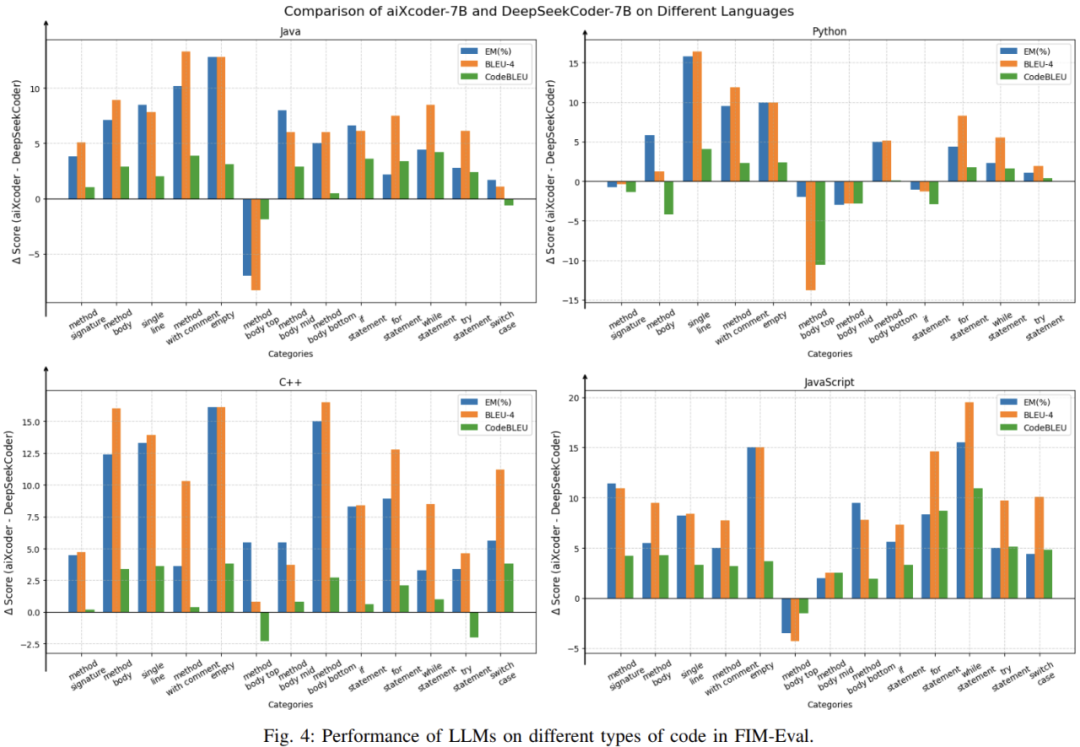
为了进一步测评 aixcoder-7B 在多种情况下的代码补全能力,团队从方法签名、方法体、方法局部、条件块、循环块、异常捕捉块等维度评估了模型在代码补全上的效果,如论文图 4 所示。对比 DeepSeekcoder-6.7B,aixcoder-7B 大部分的补全位置都拥有更好的效果。
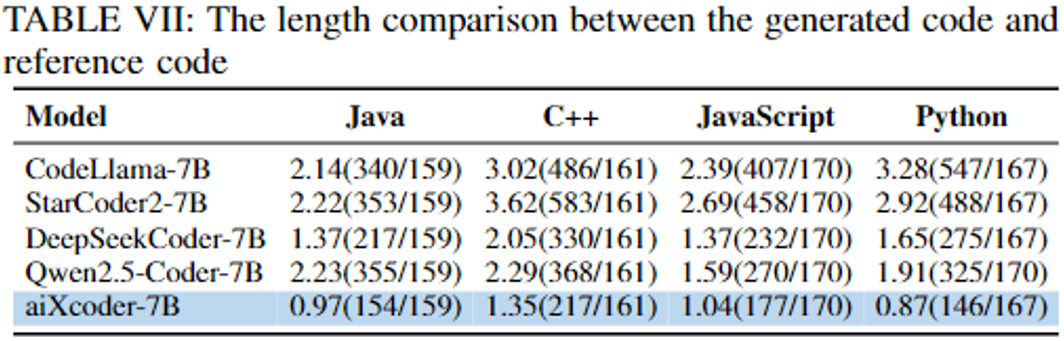
此外,因为预训练任务充分考虑了代码的语法结构,模型在推理过程中对代码的上下文结构展现出更出色的感知能力,能够准确判断需要补全完整的语法结构,并倾向生成更短的代码片段。如论文表 6 所示,模型生成的 Token 数与 GroundTruth Token 数的比值,aiXcoder -7B 更小,表明 SFIM 预训练任务有效指导了模型更好学会如何终止预测。
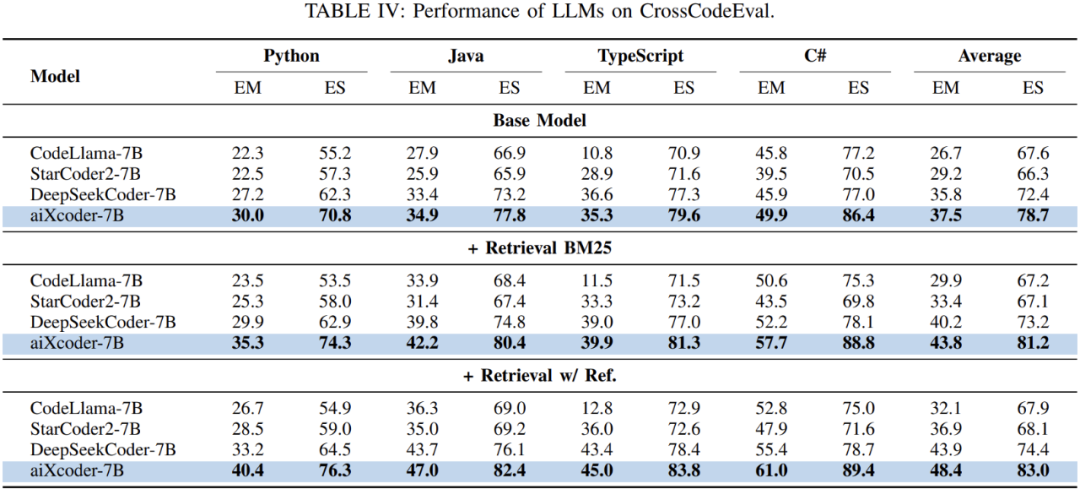
对于代码补全任务,另外一个比较重要的是跨文件上下文的理解能力。aiXcoder -7b 在预训练中以项目为单位对项目内的代码文件进行排序,获得了更好的文件间建模能力。如表 4 所示,aiXcoder -7b 在 CrossCodeEval 评测集上拥有更好的效果,表明其利用多文件的上下文信息,补全当前代码文件能力更有优势。
后续改进方向
在真实软件开发场景中,还有很多能力是大模型未曾学习到的,重中之重即代码上下文。
实际代码补全往往需要基于不同类型的上下文(如:当前文件的上文、跨文件上下文、相似代码段),去预测后续的代码。这种复杂的上下文形式与基础模型预训练时的上下文形式不一致,从而限制了基础模型在实际应用时的代码补全准确率。
为解决这个问题,研究团队在 aiXcoder 7B 上做了更多的对齐训练实验。该对齐训练有效地将模型对齐到真实软件开发场景中的上下文形式,显著地提升了模型在多种语言上的代码补全准确率。例如,在四种语言(Python、Java、C++和Go)的多行补全上,相较于aiXcoder-7B,经过优化的新模型在Exact Match(完全匹配)指标上平均取得了 13 个点的绝对提升。
当前,充分利用数十年积累的软件工程经验,将代码大模型真正应用于软件开发的实际场景中,仍然是一项艰巨而复杂的任务。然而,随着不断深入的研究,代码大模型已经让「软件开发自动化」这一宏伟目标变得愈加触手可及。