Transfusion模型,单一Transformer架构同时处理文本和图像,实现高效的多模态内容生成。
原文标题:Transfusion: 单一Transformer架构中同时处理离散数据(文本) 和 连续数据(图像)
原文作者:数据派THU
冷月清谈:
Transfusion 的核心在于结合了语言建模的“下一词预测”目标和扩散模型的“去噪”目标。它使用变分自动编码器 (VAE) 将图像编码为连续的 Patch 嵌入,并与文本的离散 token 序列整合,一同输入 Transformer 模型。模型采用标准 Transformer 架构,但针对文本和图像设计了特定的编码和解码层,并结合两种模态的损失函数进行联合优化。
实验结果表明,Transfusion 在文本生成任务中 perplexity 与传统语言模型相近,但计算效率更高;在图像生成任务中 FID 显著优于传统方法,尤其在计算资源有限的情况下;在跨模态生成任务中,Transfusion 也表现出优越的语义一致性。
Transfusion 的优势在于无需将图像离散化,从而避免了信息损失。它通过在单个模型中同时处理文本和图像,提高了多模态生成任务的性能和计算效率,为构建统一多模态生成框架提供了重要启发。
怜星夜思:
2、Transfusion 模型中提到的“联合语言建模和扩散模型的目标”,具体是如何实现的?这种联合训练方式会带来哪些挑战?
3、Transfusion 模型未来有哪些值得期待的研究方向?例如,如何改进模型结构或训练方法以进一步提升性能?
原文内容

来源:深度图学习与大模型LLM本文约2000字,建议阅读6分钟
本文为大家分享一篇关于多模态生成模型的研究论文。
介绍《Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model》
大家好,今天为大家分享一篇关于多模态生成模型的研究论文——《Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model》。该论文提出了一种新方法,能够在。这一方法通过联合语言建模和扩散模型的目标,展示了多模态生成任务在性能和计算效率上的突破,为构建统一多模态生成框架提供了重要启发。

0. 基本信息
-
标题: Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
-
作者: Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, Omer Levy
-
研究机构: Meta, Waymo, University of Southern California
-
发表时间与平台: 2024年8月,arXiv
-
DOI或链接: https://arxiv.org/abs/2408.11039

1. 主要内容
这篇论文主要探讨如何在单一Transformer架构中融合处理离散和连续数据的能力,通过联合语言建模的“Next-token Prediction”目标和扩散模型的“去噪”目标,实现对文本和图像的高效建模。其核心贡献包括:
-
提出了一种无需离散化图像的训练框架,使得模型能够同时生成文本和图像。
-
证明了该方法在多模态生成任务上比传统方法更高效,尤其在计算量有限的场景中。
-
展示了Transfusion在扩展规模时的性能优势,建立了多模态生成的新的基准。
推荐这篇论文的理由在于其为解决多模态建模挑战提供了一种新路径,显著改善了多模态任务的生成效果,同时提升了计算效率。
2. 研究背景
在生成式AI的快速发展中,文本生成和图像生成分别由语言模型(LLM)和扩散模型主导。然而,这两类模型擅长处理不同模态的数据,各自的优势难以直接迁移到另一模态:
-
离散模态(如文本):语言模型通过“下一词预测”任务训练,能够高效捕捉语言语义和上下文关系,在文本生成、问答等任务中表现优异。
-
连续模态(如图像):扩散模型通过逆向噪声去除学习生成高质量图像,是目前图像生成的主流方法。
现有方法局限
-
模态分离:大多数方法依赖于将离散模态(文本)与连续模态(图像)分别建模,难以在一个框架中同时处理两种模态。
-
图像离散化的劣势:传统方法将图像量化为离散令牌后再与文本共同建模,简化了模型架构,但带来了信息损失,尤其是图像细节。
-
计算效率瓶颈:现有多模态方法通常需要高昂的计算资源,难以在有限算力下扩展。
作者提出了一种新的训练方法,通过将语言模型和扩散模型的核心目标结合,创建一个统一的多模态模型。目标是实现高质量的文本和图像生成,同时提高训练和推理的效率。
3. 方法
Transfusion方法在单一Transformer框架内结合两种模态的训练目标,主要包括以下几个关键模块:
数据表示
Transfusion支持两种模态的数据:
-
文本通过标准的分词器转化为离散的令牌序列。
-
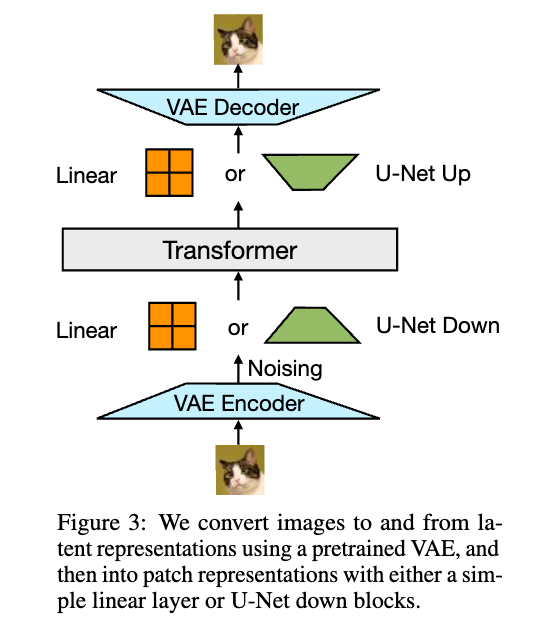
图像则通过变分自动编码器(VAE)编码为连续的Patch嵌入,每个Patch对应图像的一个小块,保留了图像的空间信息。
在混合模态的情况下,图像和文本会被整合成一个统一的序列,并通过特定标记符(如 和 )区分模态。
模型架构
Transfusion的核心是一个标准的Transformer架构,但针对两种模态设计了特定的编码和解码层:
-
文本:使用标准的嵌入层,将离散令牌转化为向量。
-
图像:使用VAE生成连续嵌入表示,结合线性层或U-Net模块进一步压缩图像数据。
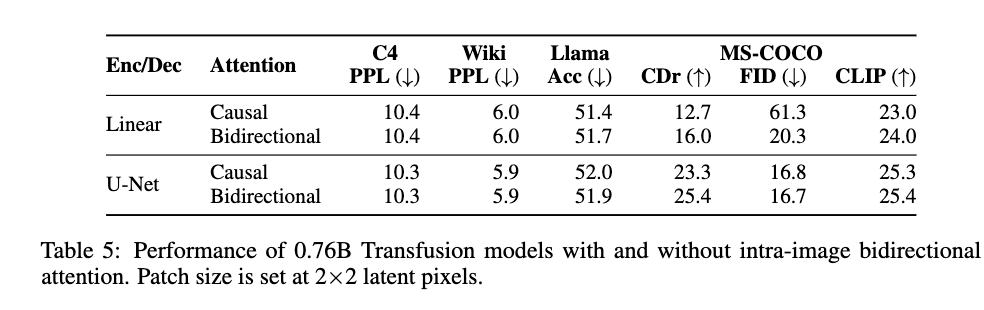
Transformer本体负责对整合后的模态序列进行建模。对于文本,使用因果注意力;对于图像,则允许双向注意力以增强图像内部信息的流动性。
训练目标
Transfusion结合了语言模型和扩散模型的损失函数:
![]()
-
:语言建模目标,预测序列中每个文本令牌的条件概率。
-
:扩散模型目标,通过去噪重建原始图像。
这种联合优化方法允许模型同时处理文本生成和图像生成任务。
推理策略
Transfusion的推理阶段结合了文本和图像生成的流程:
-
当模型预测出 标记时,切换至扩散生成模式生成图像。
-
当预测出 标记时,返回文本生成模式。
通过这种动态切换,Transfusion能够生成多模态的复杂内容。

4. 实验与发现
为了验证Transfusion的有效性,作者进行了大量实验,涵盖文本生成、图像生成以及跨模态任务。
实验设置
-
数据集:
-
文本:Wikipedia和C4语料。
-
图像:MS-COCO数据集。
-
评估指标:
-
文本生成:困惑度(Perplexity)。
-
图像生成:FID(衡量图像质量)和CLIP得分(衡量图像与文本的语义一致性)。
主要发现
-
文本生成任务:
-
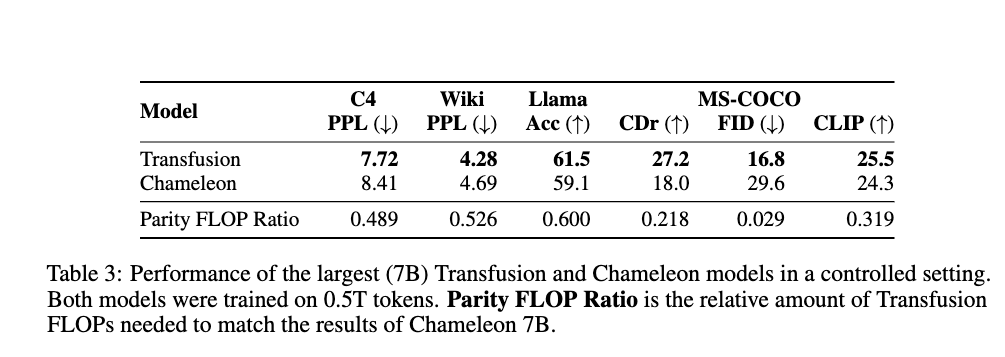
Transfusion在困惑度上与传统语言模型表现接近,但计算效率显著提升。

-
图像生成任务:
-
Transfusion的FID显著好于传统方法,尤其在计算资源有限的情况下,表现尤为突出。
3.跨模态生成任务:
-
Transfusion在图文对生成任务中表现出优越的语义一致性,表明模型能够有效结合两种模态的信息。
关键组件的影响
通过消融实验,作者发现:
-
双向注意力:对图像生成质量至关重要,可显著降低FID。
-
U-Net模块:在图像压缩和重建任务中表现优于线性层。
-
损失函数权重( ):调整损失权重能够有效平衡文本和图像生成的性能。
研究局限
尽管Transfusion方法表现优异,但仍存在一些局限性:推理阶段的时间开销较高,尚需进一步优化。尚未验证对其他模态(如音频、视频)的扩展能力。
