全新 AI 基准测试 HLE 挑战人类知识极限,当前 SOTA 模型准确率均低于 10%,预示着 AI 发展仍有巨大空间。
原文标题:DeepSeek-R1、o1都低于10%,人类给AI的「最后考试」来了,贡献者名单长达两页
原文作者:机器之心
冷月清谈:
AI 安全中心与 Scale AI 联合发布名为"人类的最后考试"(HLE)的全新基准测试,旨在评估 AI 模型在人类知识前沿的表现。HLE 包含 3000 道跨越百余学科的难题,涵盖数学、人文科学和自然科学等领域,主要由多项选择题和简答题组成,答案明确且易于验证,但无法通过网络搜索快速获取。
HLE 数据集的构建依靠全球近千名专家学者的贡献,问题经过严格的提交和审核流程,确保质量和难度。为激励高质量投稿,还设立了 50 万美元的奖金池。
目前测试结果显示,即使是最先进的 AI 模型,如 DeepSeek-R1、GPT-4 等,在 HLE 上的准确率也均低于 10%。模型的校准误差也较大,经常以高置信度给出错误答案。此外,具有推理能力的模型需要更多的计算资源才能提高性能。
尽管当前 AI 模型在 HLE 上表现不佳,但研究团队预计,随着 AI 的快速发展,到 2025 年底,模型在 HLE 上的准确率可能会超过 50%。虽然 HLE 主要测试模型在结构化学术问题上的表现,并非开放式研究或创造性解决问题的能力,但它为评估 AI 的技术知识和推理能力提供了重要指标。
HLE 数据集的构建依靠全球近千名专家学者的贡献,问题经过严格的提交和审核流程,确保质量和难度。为激励高质量投稿,还设立了 50 万美元的奖金池。
目前测试结果显示,即使是最先进的 AI 模型,如 DeepSeek-R1、GPT-4 等,在 HLE 上的准确率也均低于 10%。模型的校准误差也较大,经常以高置信度给出错误答案。此外,具有推理能力的模型需要更多的计算资源才能提高性能。
尽管当前 AI 模型在 HLE 上表现不佳,但研究团队预计,随着 AI 的快速发展,到 2025 年底,模型在 HLE 上的准确率可能会超过 50%。虽然 HLE 主要测试模型在结构化学术问题上的表现,并非开放式研究或创造性解决问题的能力,但它为评估 AI 的技术知识和推理能力提供了重要指标。
怜星夜思:
1、HLE 测试的题目难度很高,即使是人类也很难全部答对,这是否意味着 HLE 并不适合作为评估 AI 的基准?
2、HLE 的题目无法通过网络搜索快速获取答案,这是否意味着 HLE 测试的是 AI 的记忆能力而不是推理能力?
3、文章预测到 2025 年底,模型在 HLE 上的准确率可能会超过 50%,你认为这一预测是否过于乐观?
2、HLE 的题目无法通过网络搜索快速获取答案,这是否意味着 HLE 测试的是 AI 的记忆能力而不是推理能力?
3、文章预测到 2025 年底,模型在 HLE 上的准确率可能会超过 50%,你认为这一预测是否过于乐观?
原文内容
机器之心报道
编辑:Panda
随着 AI 大模型在一个又一个的任务上达到乃至超越人类水平,人类文明似乎已经进入了与 AI 共生的时代。
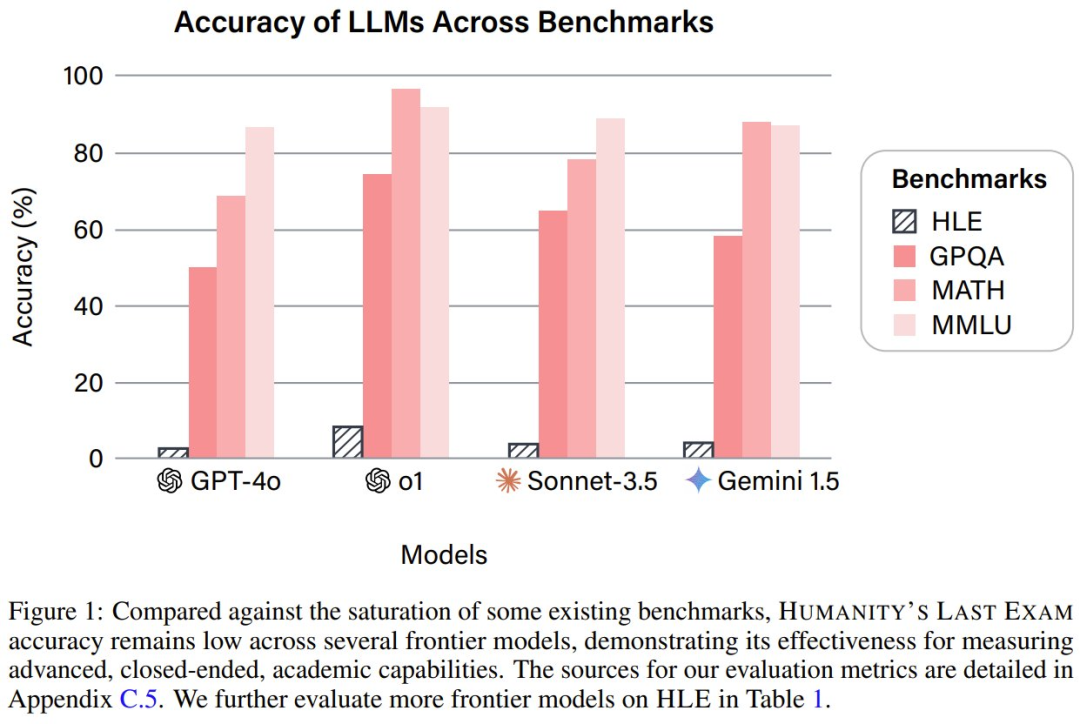
为了跟踪 AI 的发展进度,适当的基准必不可少。但现在,由于 AI 发展的速度实在太快,已有的基准已经开始不够用了。比如在常用的基准 MMLU 上,当今前沿的 LLM 已经能达到超过 90% 的准确度了!这就限制了对前沿 LLM 能力的精确度量能力。
基于此现状,Center for AI Safety(AI 安全中心)与 Scale AI 联合打造一个名字相当吸引眼球的新基准:Humanity's Last Exam,即「人类的最后考试」,简称 HLE。

-
论文标题:Humanity’s Last Exam
-
论文地址:https://arxiv.org/pdf/2501.14249
-
项目地址:https://lastexam.ai
从名字也能看出来,其背后必然有一个雄心勃勃的团队。据介绍,HLE 是一个「位于人类知识前沿的多模态基准」,其设计目标是成为「同类中具有广泛学科覆盖范围的终极封闭式学术基准。」
现目前,HLE 已包含 3000 个问题,涉及上百门学科,包括数学、人文科学和自然科学。其中的问题主要由适合自动评估的多项选择题和简单问答题构成;每个问题都有一个已知的解,该解非常明确且易于验证,但无法通过互联网检索快速回答。
为了构建 HLE 基准,Center for AI Safety 与 Scale AI 向全球不同学科的专家寻求了帮助,最终让该论文有了一份长达两页、近千人的数据集贡献者名单:


该团队也使用该基准测试了一些 SOTA 模型,结果如下。很显然,HLE 相当难。
数据集
HLE 包含 3000 多个高难度问题,涉及一百多个科目,概况见下图 3 。

下面展示了一些问题示例:
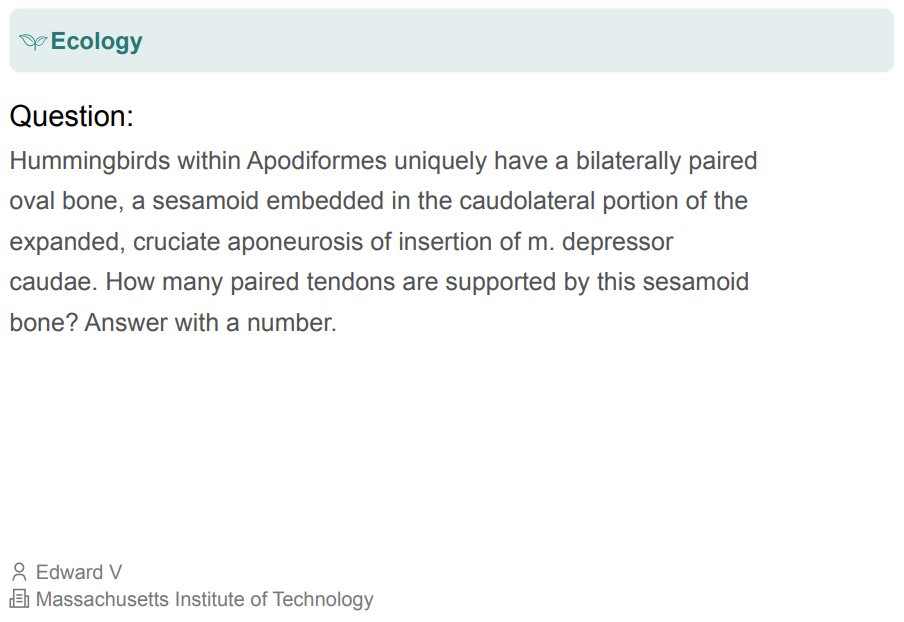
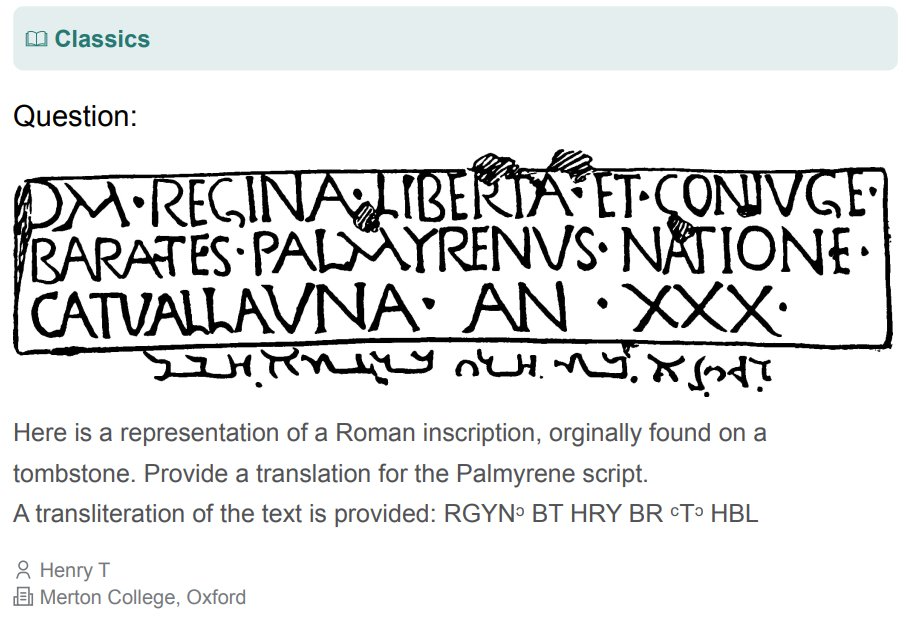


虽然这些问题已公开发布,但该团队也表示还维护着一个私有的测试集,其中包含一些用来评估模型过拟合现象的问题。
收集数据集
该团队在技术报告中分享了 HLE 基准数据集的收集过程:「HLE 是一项全球合作的成果,其中的问题来自 50 个国家 / 地区的 500 多个机构的近 1000 名学科专家贡献者 —— 主要由教授、研究人员和研究生学位持有者组成。」
问题风格:HLE 包含两种问题格式:精确匹配问题(模型提供确切的字符串作为输出)和多项选择题(模型从五个或更多答案选项中选择一个)。HLE 是一个多模态基准,其中 10% 的问题需要同时理解文本和图像。80% 的问题是精确匹配型问题,其余的是多项选择题。
提交格式:为确保问题的质量和完整性,该团队设定了严格的提交标准。
-
问题应该准确、明确、可解且不可搜索,确保模型不能依赖记忆或简单的检索方法。
-
所有提交内容必须是原创的,或者是基于已发表信息的非平凡合成版本,但也会接受未发表的研究。
-
问题通常需要研究生水平的专业知识或高度特定主题的测试知识(例如,精确的历史细节、琐事、当地习俗),并且有领域专家接受的具体、明确的答案。
-
当 LLM 能提供正确答案但推理有误时,希望作者能修改问题参数,例如答案选项的数量,以阻止假正例。
-
要求明晰的英语和精确的技术术语,并在必要时支持 LATEX 标注。
-
答案要简短,并且对于精确匹配的问题,答案要容易验证,以支持自动评分。
-
禁止开放式问题、主观解释题和与大规模杀伤性武器有关的内容。
-
每个问题都应附有详细的解答以验证准确性。
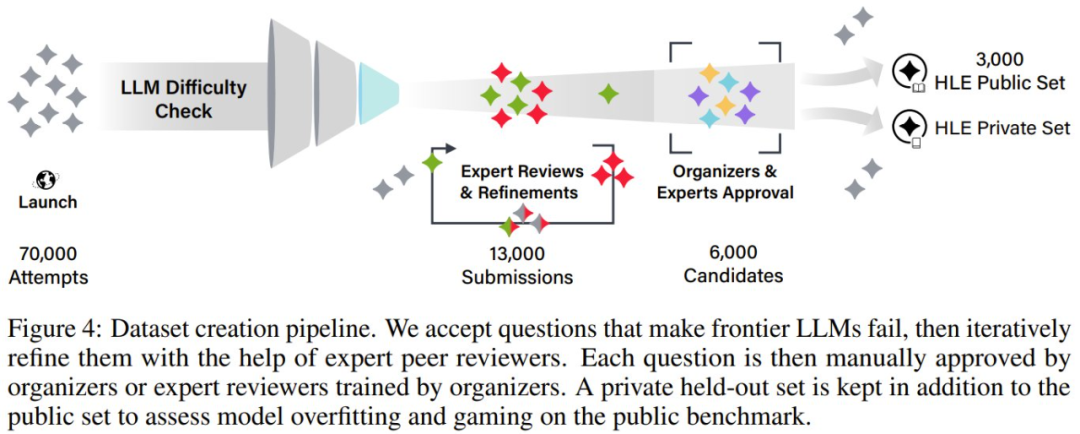
奖金池:为了吸引高质量的投稿,该团队还设立了一个奖金池,其中包含 50 万美元。对于前 50 个问题,每个奖金 5000 美元,接下来的 500 个问题每个奖金 500 美元,具体由组织者决定。正是由于这种这种激励结构,加上任何被 HLE 接收的问题的作者都有机会成为论文合著者,吸引了有资历专家的参与,尤其是那些在其领域内拥有高级学位或丰富技术经验的专家。
收集完成后,该团队还组织人手对收集到的问题进行了审核,下图展示了其审核流程:
当前 SOTA 模型在该基准上表现如何?
有了基准,自然得对当前的模型进行一番评估。该团队评估了 SOTA 模型在 HLE 上的性能表现,并分析了它们在不同问题类型和领域上的能力。
这些模型表现如何呢?如下表所示,整体表现可以总结为一个字:差。
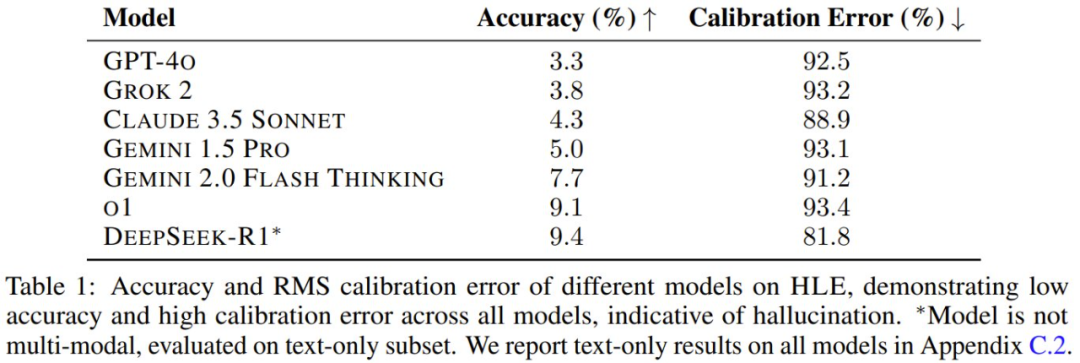
从 GPT-4o 到 DeepSeek-R1,当前最佳的模型的准确度表现都没能超过 10%。目前官网也已经更新了 o3-mini 的成绩,其中 high 版本能达到 13%:

OpenAI CEO Sam Altman 还表示 o3-mini-high 如果使用 ,则其在 HLE 上的准确度更能倍增至 26.6%。

该团队表示:「如此低分的部分原因是设计使然 —— 数据集收集过程试图过滤掉现有模型可以正确回答的问题。然而,我们在评估时注意到,这些模型的准确度也都不是零。这是由于模型推理中固有的噪声 —— 模型可能会不一致地猜对正确答案,或者猜中多项选择题答案的概率低于随机。」因此,这些模型在该数据集上的真正能力底线仍然是未知的,接近零准确度的微小变化并不能有力地表明进展。
鉴于这些模型在 HLE 上表现不佳,该团队表示应该在考虑到不确定性的前提下校准模型,而不是自信地提供错误答案,毕竟模型存在虚构/幻觉现象。为了测量校准误差(Calibration Error),该团队让模型提供答案的同时还提供置信度(范围是 0% 到 100%)。经过良好校准的模型声明的置信度应该与其实际准确度相匹配 —— 例如,在声称置信度为 50% 的问题上实现 50% 的准确度。
而表 1 的结果表明所有模型的校准都很差。在 HLE 上,模型经常以高置信度提供错误答案,这表明这些模型无法分辨这些问题何时超出其能力范围。
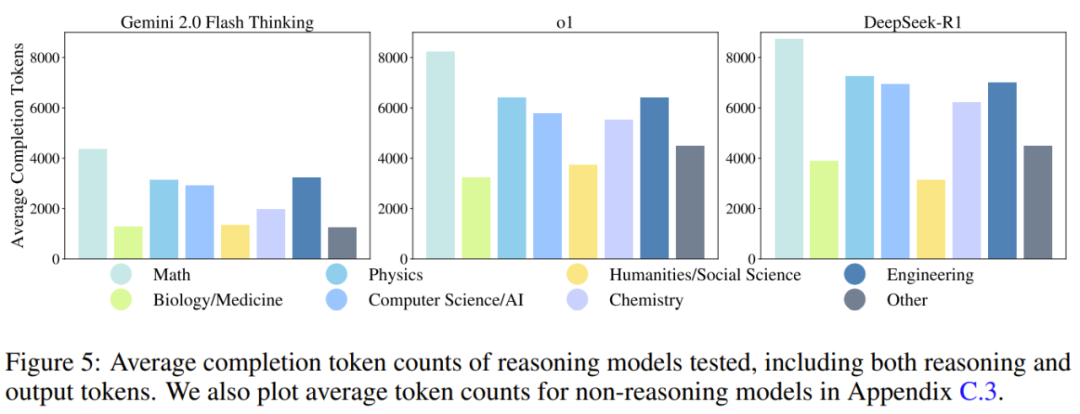
token 数量:具有推理能力的模型需要更多的推理时间计算。为了在评估中阐明这一点,该团队分析了各个模型使用的完成 token 的数量。如图 5 所示,所有推理模型都需要生成比非推理模型多得多的 token 才能提高性能。该团队指出:「未来的模型不仅应该提升准确度,还应该努力实现计算优化。」
讨论
该团队表示,虽然目前的 LLM 在 HLE 上的准确度非常低,但最近的历史表明,这个基准很快就会饱和 —— 前沿模型的性能可在短时间内从接近零到接近完美。
他们预计,到 2025 年底,模型在 HLE 上的准确度就可能超过 50%。
如果模型能在 HLE 上取得高准确度表现,则说明其在封闭式、可验证的问题和前沿的科学知识上具备了专家级的表现,但仅靠这个基准,并不能表明模型已经具备自主研究能力或者已经是所谓的「通用人工智能」。HLE 测试的是结构化的学术问题,而不是开放式研究或创造性解决问题的能力,因此这是一个重点关注技术知识和推理的测量指标。
该团队写到:「HLE 可能是我们需要对模型进行的最后的学术考试,但它远非 AI 的最后一个基准。」
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com