LLaVA-Mini 来了!通过将每张图像压缩至 1 个视觉 token,显著提升图像视频理解效率,实现更低延迟的实时多模态交互。
原文标题:LLaVA-Mini来了!每张图像所需视觉token压缩至1个,兼顾效率内存
原文作者:机器之心
冷月清谈:
中国科学院计算技术研究所自然语言处理团队发布了高效多模态大模型LLaVA-Mini,该模型通过将每张图像所需的视觉token压缩至1个,在保持视觉理解能力的同时,显著提升了图像和视频理解的效率。
LLaVA-Mini的核心创新在于对视觉token的压缩和模态预融合。基于对LLMs中视觉token处理过程的分析,研究团队发现视觉token主要在LLMs的早期层起作用。LLaVA-Mini利用基于查询的压缩模块,将图像编码为单个视觉token,并通过模态预融合模块将视觉信息融入文本token,从而在压缩视觉token的同时保留视觉信息。
实验结果表明,LLaVA-Mini在图像理解和视频理解方面均取得了与现有模型相当甚至更优的性能,同时计算效率提升77%,响应延迟降低至40毫秒,显存占用显著减少,支持长时间视频处理。
LLaVA-Mini的优势在于其高效性,使其能够支持实时多模态交互,但也存在一些局限性,例如在处理OCR等精细化视觉任务时性能可能受影响。
LLaVA-Mini的核心创新在于对视觉token的压缩和模态预融合。基于对LLMs中视觉token处理过程的分析,研究团队发现视觉token主要在LLMs的早期层起作用。LLaVA-Mini利用基于查询的压缩模块,将图像编码为单个视觉token,并通过模态预融合模块将视觉信息融入文本token,从而在压缩视觉token的同时保留视觉信息。
实验结果表明,LLaVA-Mini在图像理解和视频理解方面均取得了与现有模型相当甚至更优的性能,同时计算效率提升77%,响应延迟降低至40毫秒,显存占用显著减少,支持长时间视频处理。
LLaVA-Mini的优势在于其高效性,使其能够支持实时多模态交互,但也存在一些局限性,例如在处理OCR等精细化视觉任务时性能可能受影响。
怜星夜思:
1、LLaVA-Mini将视觉token压缩到极致,这对于模型处理抽象概念或复杂场景的理解能力会有哪些影响?
2、相比于其他多模态模型,LLaVA-Mini的单token策略在实际应用场景中有哪些独特的优势和劣势?
3、未来,LLaVA-Mini这类压缩视觉token的模型是否会成为多模态模型的主流发展方向?
2、相比于其他多模态模型,LLaVA-Mini的单token策略在实际应用场景中有哪些独特的优势和劣势?
3、未来,LLaVA-Mini这类压缩视觉token的模型是否会成为多模态模型的主流发展方向?
原文内容
![]()
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:[email protected];[email protected]
以 GPT-4o 为代表的实时交互多模态大模型(LMMs)引发了研究者对高效 LMM 的广泛关注。现有主流模型通过将视觉输入转化为大量视觉 tokens,并将其嵌入大语言模型(LLM)上下文来实现视觉信息理解。然而,庞大的视觉 token(vision token)量显著增加了 LMMs 的计算复杂度和推理延迟,尤其在高分辨率图像或视频处理的场景下,效率问题愈加突出。因此,提高多模态大模型的计算效率成为实现低延时实时交互的核心挑战之一。

为了应对这一挑战,中国科学院计算技术研究所自然语言处理团队创新性的提出了高效多模态大模型 ——LLaVA-Mini。通过对 LMMs 中视觉 tokens 处理过程的可解释性分析,LLaVA-Mini 将每张图像所需的视觉 tokens 压缩至 1 个,并在确保视觉理解能力的同时显著提升了图像和视频理解的效率,包括:计算效率提升(FLOPs 减少 77%)、响应时延降低(响应延时降至 40 毫秒)、显存占用减少(从 360 MB / 图像降至 0.6MB / 图像,支持 24GB GPU 上进行长达 3 小时的视频处理)。

-
论文题目:LLaVA-Mini: Efficient Image and Video Large Multimodal Models with One Vision Token
-
论文链接:https://arxiv.org/abs/2501.03895
-
开源代码:https://github.com/ictnlp/LLaVA-Mini
-
模型下载:https://huggingface.co/ICTNLP/llava-mini-llama-3.1-8b
多模态大模型如何理解视觉 Tokens?
为了在减少视觉 token 的同时保持视觉理解能力,研究者首先分析了 LMMs 如何处理和理解大量视觉 token。分析集中在 LLaVA 架构,特别从注意力机制的角度探讨了视觉 token 的作用及其数量对 LMMs 性能的影响。具体而言,实验评估了视觉 token 在 LMMs 不同层中的重要性,涵盖了多种 LMMs,以识别不同规模和训练数据集的模型之间的共性。

视觉 token 在 LMMs 不同层中获取的注意力权重

LMMs 中不同层的注意力可视化
分析发现:
1. 视觉 token 在前几层中的重要性较高:在 LMMs 的前几层,视觉 token 获得了更多的注意力,但随着层数增加,注意力迅速转向指令 token(文本),超过 80% 的注意力集中在指令 token 上。这表明,视觉 token 主要在前层发挥作用,文本 token 通过注意力机制从视觉 token 中获取视觉信息,而后续层则依赖于已经融合视觉信息的指令 token 来生成回复。
2. 大部分视觉 token 在前几层中被关注:如上图注意力可视化所示,早期层中几乎所有视觉 token 都受到均匀关注,而在后期层,模型则集中注意力于少数几个视觉 token。这表明,直接减少所有层中的视觉 token 数量不可避免地会导致视觉信息的丢失。
更多分析请参考论文。通过预先分析,研究者发现视觉 token 在 LMMs 的早期层中起着至关重要的作用,在这一阶段,文本 token 通过关注视觉 token 融合视觉信息。这一发现为 LLaVA-Mini 极限压缩视觉 token 的策略提供了重要的指导。
LLaVA-Mini 介绍
LLaVA-Mini 使用视觉编码器将图像编码为若干视觉 token。为了提升效率,LLaVA-Mini 通过压缩模块大幅减少输入 LLM 底座的视觉 token 数量。为了在压缩过程中保留视觉信息,基于先前的研究发现,视觉 token 在早期层中对于融合视觉信息至关重要,LLaVA-Mini 在 LLM 底座之前引入了模态预融合模块,将视觉信息融入文本 token 中,从而确保视觉理解能力。
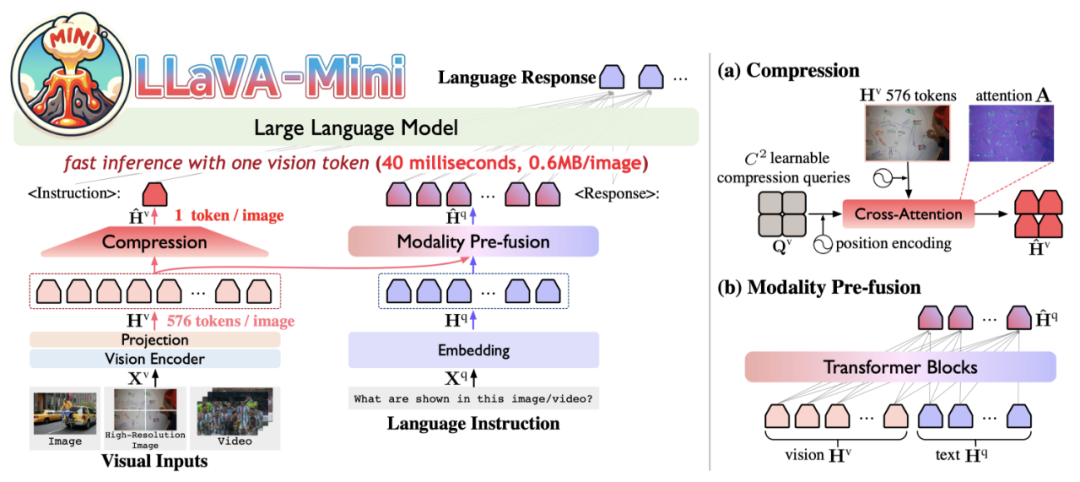
视觉 token 压缩
LLaVA-Mini 通过基于查询的压缩模块(query-based compression)减少输入 LLM 底座的视觉 token 数量。为学习视觉 token 的压缩,LLaVA-Mini 引入若干可学习的压缩查询(query),通过交叉注意力机制与所有视觉 token 交互,选择性提取关键的视觉信息,生成压缩后的视觉 token。当压缩查询数量为 1 时,LLaVA-Mini 仅用一个视觉 token 表示一张图像。
模态预融合
视觉 token 的压缩不可避免地会丢失部分视觉信息。为了在压缩过程中尽可能保留更多的视觉信息,LLaVA-Mini 在 LLM 底座前引入模态预融合模块,文本 token 预先融合来自所有视觉 token 的相关视觉信息。基于之前的发现,视觉文本信息融合通常发生在 LLM 底座的早期层,而 LLaVA-Mini 将这种融合过程显示地提取到 LLM 外部进行,从而减少计算量。
最终,LLaVA-Mini 将输入 LLM 底座的 token 数量从 “576 个视觉 token+N 个文本 token” 压缩至 “1 个视觉 token+ N 个模态融合 token”。通过此,LLaVA-Mini 能够更高效地完成图像理解和视频理解。
实验结果
在本文的实验中,研究者在 11 个图像理解基准和 7 个视觉理解基准上评估了 LLaVA-Mini 的性能以及效率优势,以下是所得的关键实验结果。
图像理解评估

如上表所示,研究者在 11 个基准测试上比较了 LLaVA-Mini 和 LLaVA-v1.5。结果表明,LLaVA-Mini 仅使用 1 个视觉 token(压缩率 0.17%),远低于 LLaVA-v1.5 的 576 个视觉 token,取得与 LLaVA-v1.5 相当的图像理解能力。
视频理解评估

如上表所示,LLaVA-Mini 在视频理解上优于目前先进的视频 LMMs。这些视频 LMMs 使用大量视觉 token 表示每帧(224 或 576),受限于上下文长度,仅能提取 8-16 帧,可能导致部分视频信息丢失。相比之下,LLaVA-Mini 通过 1 个视觉 token 表示每张图像,能够以每秒 1 帧的速度提取视频帧,从而在视频理解上表现更佳。
长视频理解评估

研究者进一步将 LLaVA-Mini 与先进的长视频 LMMs(能够处理超过 100 帧的视频)在长视频基准 MLVU 和 EgoSchema 上进行比较。
如上表所示,LLaVA-Mini 在长视频理解上具有显著优势。通过将每帧表示为一个视觉 token,LLaVA-Mini 在推理时能够轻松扩展到更长的视频,并且通过 token 之间的位置编码隐式建模时序关系。特别地,LLaVA-Mini 仅在少于 1 分钟(< 60 帧)的视频上进行训练,且在推理时能够处理超过 2 小时(> 7200 帧)的长视频。
LLaVA-Mini 效率提升

效率优势是 LLaVA-Mini 的一大亮点。如上图所示,与 LLaVA-v1.5 相比,LLaVA-Mini 显著减少了 77% 的计算负载,实现了 2.9 倍的加速。LLaVA-Mini 的响应延迟低于 40 毫秒,这对于开发低延迟实时 LMMs 至关重要。

视频处理是 LMMs 面临的另一个挑战,特别是在显存消耗方面。上图展示了 LMMs 在处理不同长度视频时的内存需求。以往的方法每张图像需要约 200-358 MB 的内存,使得它们在 40GB GPU 上仅能处理约 100 帧。相比之下,LLaVA-Mini 仅需 0.6 MB 内存即可处理每张图像,理论上可在 24GB 内存的 RTX 3090 上支持处理超过 10,000 帧的视频。
视觉 token 压缩效果

为验证 LLaVA-Mini 将图片压缩成 1 个视觉 token 的有效性,上图可视化了压缩过程中的交叉注意力。在不同类型和风格的图像(如照片、文本、截图和卡通图)中,LLaVA-Mini 的压缩展现了强大的可解释性,能够有效地从图像中提取关键的视觉信息。
总结
LLaVA-Mini 是一个统一的多模态大模型,能够高效地支持图像、高分辨率图像和视频的理解。LLaVA-Mini 在图像和视频理解方面表现出色,同时在计算效率、推理延迟和内存使用上具有优势,促进了高效 LMM 的实时多模态交互。
不过,LLaVA-Mini 也存在一些局限,主要表现在处理一些 OCR 等精细化视觉任务时,压缩成 1 个视觉 token 势必会影响其性能。但由于 LLaVA-Mini 的灵活性,在使用时可根据具体场景设置压缩后的视觉 token 数量,从而在性能和效率中取得权衡。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:[email protected]