Adobe推出MotionBridge,实现多模态控制的插帧视频生成和编辑,效果惊艳!
原文标题:多重可控插帧视频生成编辑,Adobe这个大一统模型做到了,效果惊艳
原文作者:机器之心
冷月清谈:
Adobe最新推出的MotionBridge模型,在视频生成和编辑方面实现了多模态控制的突破。该模型不仅支持传统的图像生成动画,还允许用户通过关键帧、运动轨迹、掩码、引导像素和文本等多种方式进行精确控制。
MotionBridge以插帧为核心框架,通过补充帧之间的过渡,生成流畅的视频。它克服了传统插帧方法在处理大动作和细节控制方面的局限性,并解决了现有视频生成模型可控性不足的问题。
该模型采用DiT架构,并具有普适性,适用于各种DiT模型。它使用双分支编码器分别处理内容控制和运动控制信号,提高了控制的精准度。此外,MotionBridge还引入了一种新的运动轨迹表示方法,以及空间内容控制机制,使用户能够更灵活地进行创作。
通过curriculum learning训练策略,MotionBridge能够逐步学习各种控制方式,并生成高质量的视频。实验结果表明,MotionBridge在生成细节、动作流畅性和可控性方面均优于现有方法。
MotionBridge以插帧为核心框架,通过补充帧之间的过渡,生成流畅的视频。它克服了传统插帧方法在处理大动作和细节控制方面的局限性,并解决了现有视频生成模型可控性不足的问题。
该模型采用DiT架构,并具有普适性,适用于各种DiT模型。它使用双分支编码器分别处理内容控制和运动控制信号,提高了控制的精准度。此外,MotionBridge还引入了一种新的运动轨迹表示方法,以及空间内容控制机制,使用户能够更灵活地进行创作。
通过curriculum learning训练策略,MotionBridge能够逐步学习各种控制方式,并生成高质量的视频。实验结果表明,MotionBridge在生成细节、动作流畅性和可控性方面均优于现有方法。
怜星夜思:
1、MotionBridge与其他视频生成模型相比,最大的优势是什么?除了文中提到的,还有什么潜在的应用场景?
2、MotionBridge的“curriculum learning”训练策略具体是如何实现的?这种策略的优势和局限性是什么?
3、MotionBridge的开源情况如何?如果想要尝试使用或进一步研究,有哪些途径?
2、MotionBridge的“curriculum learning”训练策略具体是如何实现的?这种策略的优势和局限性是什么?
3、MotionBridge的开源情况如何?如果想要尝试使用或进一步研究,有哪些途径?
原文内容
![]()
AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文一作 Maham Tanveer 是 Simon Fraser University 的在读博士生,主要研究方向为艺术视觉生成和创作,此前在 ICCV 发表过艺术字体的生成工作。师从 Hao (Richard) Zhang, IEEE Fellow, Distinguished Professor, 并担任 SIGGRAPH 2025 Paper Chair. 本文尾作 Nanxuan (Cherry) Zhao 在 Adobe Research 担任 Research Scientist, 研究方向为多模态可控生成和编辑,有丰富的交叉方向研究经历(图形学 + 图像 + 人机交互),致力于开发可以让用户更高效进行设计创作的算法和工具。
继 Firefly 视频大模型公布后,Adobe 的研究者在如何更好的控制视频的生成和编辑进行了更深入的研究。近日,Adobe 提出了一个统一模型,除了传统的根据图片生成动画的功能(image animation)外,同时支持各种模态的控制,包括关键帧 (keyframes)、运动轨迹 (sparse trajectory)、掩码(mask)、引导像素(guiding pixels)、文本等。
论文中的 demo 让人眼前一亮,下面一起来看看模型的效果:
1. 运动轨迹 (sparse trajectory)

通过提供简单的轨迹笔画,小熊栩栩如生地动起来了。
2. 掩码(Mask)

MotionBridge 不仅可以控制物体的运动,如图所示,将简单的运动笔画和 mask 结合起来,模型也可以轻松控制镜头视角。

如上所示的 mask 描绘了变动(dynamic)区域,同样 mask 也可以指定不动的(static,红色)区域。描绘出整座桃林围着城堡旋转的景象。

让我们看看同样的图像和运动轨迹,不同 mask 作用下的结果吧。
3. 引导像素 (guiding pixels)
通过将想要的像素区域粘贴在指定帧的指定位置,就可以进行更精准的像素控制。如:船在指定时间 “航行” 到指定位置。


4. 关键帧 (keyframes)
提供关键帧,模型可以在关键帧之间生成中间帧,实现场景的平滑切换。在视频内容创作、动画制作、视频合成等方面都有至关重要的作用,例如长视频合成 / 生成。除了可以生成有别于以往插帧方法更丰富困难的动作,还可以自然和多种模态控制结合。
通过运动轨迹控制,三个小球可以自由在彭罗斯阶梯分别滚动。



加上 mask,操控飞船左右摆动也不在话下,连洒下来的光也追随移动

动静结合,万圣节装扮的动图也可以多种多样:

当采用同一帧作为首位帧,还可以产生循环播放的奇妙效果:

当然,卡通视频也不在话下:

也可以进行视角转化:


不单单可以进行新视频的生成和创作,MotionBridge 还可以改善图生视频或者文生视频的效果,减少歧义并增加视频复杂度和可控性。

除此之外,最常用的文本交互也是支持的。
更多的结果和应用,请参考官方视频。
技术概览
如今,已经有很多模型可以进行图生视频的创作,但生成的结果往往缺少可控性,用户要进行很多次的试错才能得到满意的结果。本文提出了一个名为 MotionBridge 的算法集成了多种可控信号,方便用户生成或者编辑现有的视频。不同于以往工作,MotionBridge 以插帧作为基本框架构建模型。即模型可以通过输入 1~n 张关键帧来生成对应视频,补全帧与帧之间的流畅过度。这个建模方式自然的保留了原本图生视频(image to video)的能力,同时提供了更高的可控性和视频生成质量。
然而,传统的插帧方法还具有一定的局限性,传统方法一般分为运动估计和运动补偿两个步骤,但当输入帧之间的时间或空间间隔增大时,运动估计和补偿的难度呈指数级上升。这是因为要生成逼真的中间帧,就必须填补输入帧之间缺失的信息,而这往往需要合成全新的内容,这对于传统方法而言是一个巨大的挑战。
尽管近年来视频生成模型取得了显著进展,为插帧技术带来了新的可能性,但这些技术仍然存在不足。一方面,许多模型难以生成复杂的大动作,无法满足创作者对于丰富场景变化的需求;另一方面,即使能够生成高质量的视频,却常常缺乏对中间帧细节的精细控制,导致最终生成的视频与创作者的创意设想存在偏差。
因此,为了解决以上的难题,MotionBridge 第一次进行了统一多模态可控插帧视频模型的尝试。
相比于图生视频,可控插帧视频任务的复杂度更高。以运动轨迹控制为例,视频插帧不仅需要服从指定轨迹,还需要丝滑过度并在指定帧结束。即使轨迹不完整,模型也需要根据关键帧推测,往往生成的动作比图生视频更为复杂。而进行多模态控制会进一步提升问题难度。
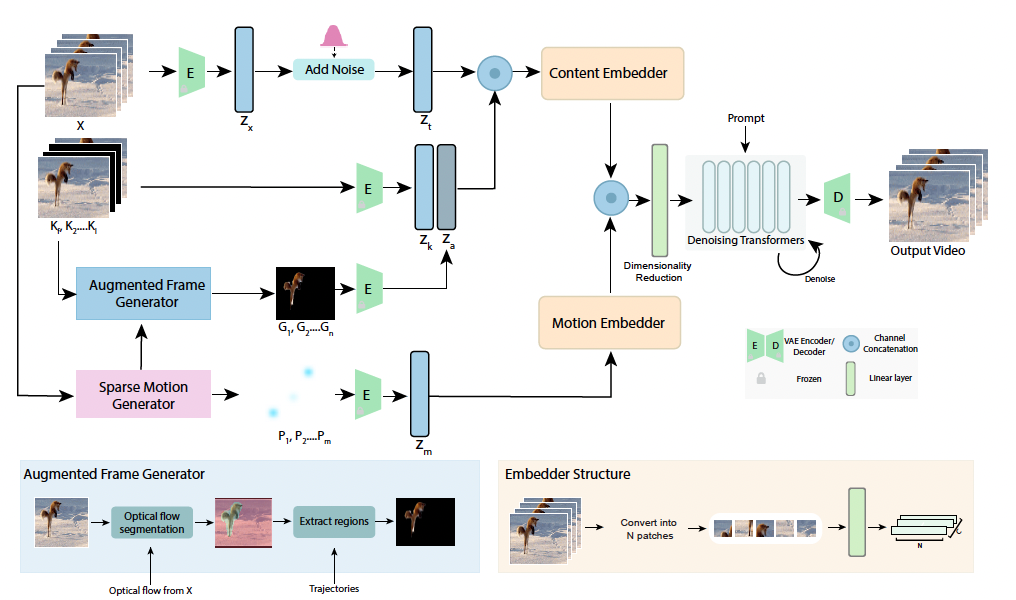
为了确保模型的生成能力,MotionBridge 的设计基于 DiT 的模型架构并且具有普适性(backbone-agnostic)可以适用于任何形式的 DiT 架构。
技术要点
1. 分类编码控制信号:为了减少控制信号融合时的歧义,MotionBridge 将控制分为内容控制(如掩码和引导像素)和运动控制(如轨迹)两类,通过双分支嵌入器分别计算所需特征,再引导去噪过程。这样的设计能更精准地处理不同类型的控制信息。
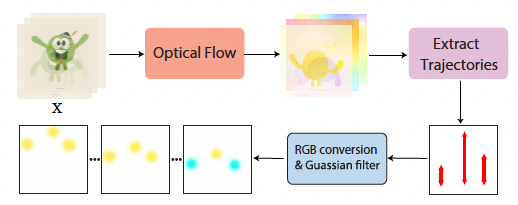
2. 运动轨迹表征:用简单且准确的交互表征方式进行视频运动的控制颇具挑战。该模型提出一种生成器,它能从光流合成轨迹,并将其转换为稀疏 RGB 点,作为模型训练时的运动表示,有效提升了运动控制的准确性。
3. 空间内容控制表征:MotionBridge 不仅有传统的轨迹控制,还增加了掩码和引导像素等空间内容控制。用户可以指定想要移动或保持静止的区域,进一步降低生成过程中的歧义,提供更灵活的创作条件。
4. 训练策略:面对多模态控制,常规训练效果不佳。MotionBridge 采用 curriculum learning 策略,先给模型输入更密集、简单的控制,再逐渐过渡到更稀疏、高级的控制,确保模型能平稳学习各种控制方式。
对比实验
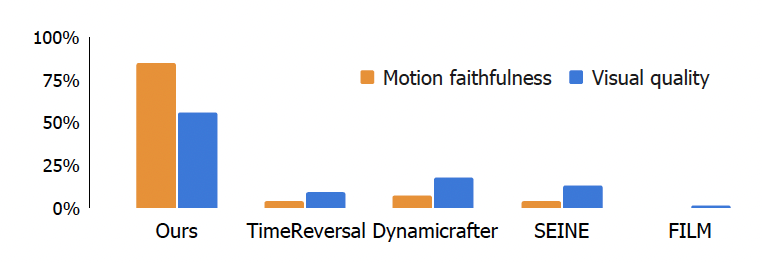
1. 与 SOTA 的算法相比,MotionBridge 在没有额外控制的干预下,可以生成更真实高质量的图片细节。并且证实了在不同 DiT 架构下的普适性。

2. 消融研究
a. 对于算法提出的分类编码融合(dual-branch)和 curriculum learning,文中也进行了实验。可以看出其设计对于模型理解轨迹控制输入以及视频生成质量起到了至关重要的作用。

b. 掩码(mask)的作用:定性实验表明在一些情况下,mask 的使用可以让模型更容易感知到主体,并且让用户可以以尽量少的交互达到想要的效果。比如当只有一个运动轨迹时,因为过于稀疏,狐狸的跳起空间有限。当额外将 mask 输入,狐狸的跳跃便更加连贯自然。而用户也不需要像之前的工作一样提供过多的轨迹笔画反复调试。

更多技术细节,对比实验请参考原文:https://motionbridge.github.io/static/motionbridge_paper.pdf
视频:https://motionbridge.github.io/static/motionbridge_1.mp4
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com