国产大模型DeepSeek-R1技术解析:开放权重、独特训练方法及强化学习策略使其超越ChatGPT,登顶美区App Store。
原文标题:“袋鼠书”作者Jay Alammar深度解析DeepSeek-R1核心技术
原文作者:图灵编辑部
冷月清谈:
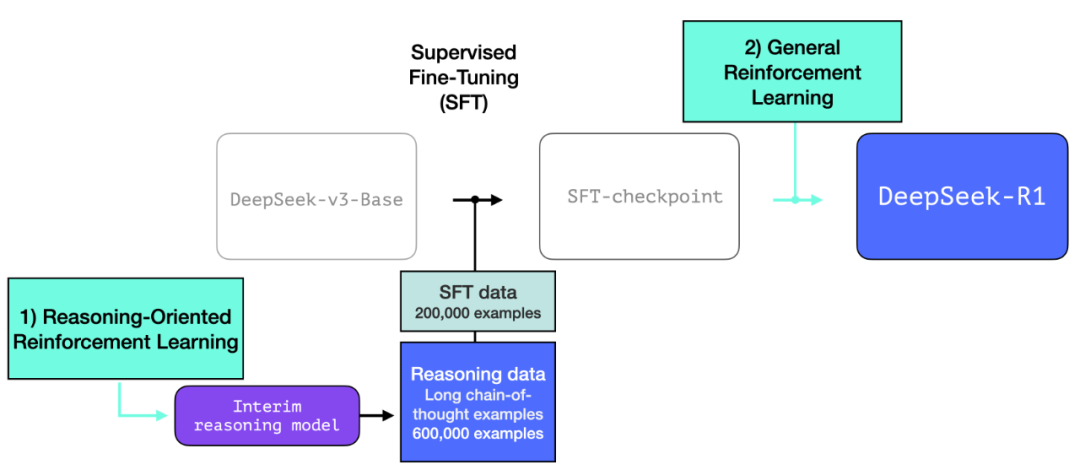
DeepSeek-R1 的训练分为三个主要步骤:
1. 长链推理监督微调(SFT):使用了 60 万个示例,这些示例获取成本很高,其生成流程是重要的技术亮点。
2. 阶段性高质量推理大语言模型:该模型并非最终模型,但专注于推理,它使用少量标注数据和强化学习构建,其输出用于训练更通用的 R1 模型。
3. 大规模强化学习(RL):分两步进行。
* R1-Zero:这个模型不使用带标签的 SFT 数据,直接从预训练模型开始,通过强化学习训练,其推理能力与 OpenAI 的 O1 模型相媲美。它利用了现代基础模型的能力和推理问题的可自动化验证特性。
* 通用强化学习:在 R1-Zero 的基础上,使用 SFT 数据和强化学习,使其在推理和其他任务上都表现出色,并引入了实用性和安全性奖励模型。
DeepSeek-R1 的架构基于 Transformer 解码器,共 61 层,前 3 层是密集全连接层,后 58 层采用专家混合架构(MoE)。
怜星夜思:
2、文章提到了 DeepSeek-R1-Zero 跳过了 SFT 阶段,直接使用强化学习。这种做法的风险是什么?为什么 DeepSeek-R1 最终没有沿用这种方式?
3、DeepSeek-R1 如何平衡推理能力和在其他非推理任务上的表现?这种平衡在实际应用中有什么意义?
原文内容
这一周真的是热闹,谁能料到,国产大模型 DeepSeek 的发布竟然引发了英伟达股价的滑跌。DeepSeek 不仅震动了硅谷,还超越了 ChatGPT,成功登顶美区 APP Store 下载第一!近日,Sam Altman 更是打破沉默,公开承认 DeepSeek 的实力,这波操作简直堪称科技界的“大地震”。
DeepSeek-R1 作为 AI 领域又一重要的进展,对机器学习研发社区来说,它的发布意义重大。

-
它是一个开放权重模型,并且提供了蒸馏版本;
-
它分享并反思了一种新的训练方法,可以用于复现类似 OpenAI O1 这样的推理型模型。
在本文中,我们将深入探讨 DeepSeek-R1 的构建过程。文前给大家带来一个好消息,本文作者 Jay Alammar 同时也是美亚畅销大模型图书 Hands-On Large Language Models 的作者,本书中文版《图解大模型》将于 2025 年 4 月上市,没错,就是下面这本👇,小伙伴们敬请期待呀!

回顾:三步创建高质量 LLM 的方法

下图是“袋鼠书”第 12 章,展示了通过三个步骤创建高质量 LLM 的一般方法:

-
语言建模:基于海量网络数据训练基础模型;
-
监督微调(SFT):提升模型指令遵循与问题解答能力;
-
偏好调整:对齐人类偏好,生成最终可用模型。
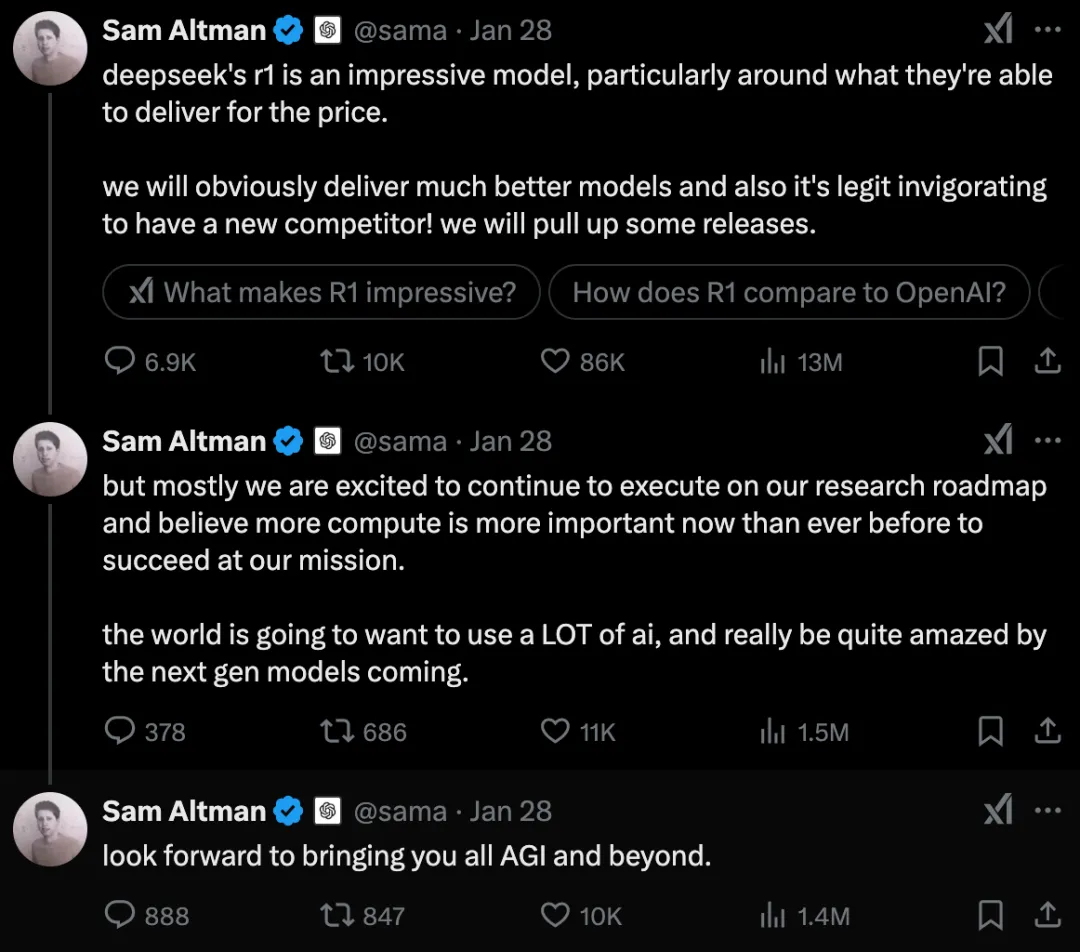
DeepSeek-R1 训练流程
DeepSeek-R1 遵循以下总体流程:模型训练第一步的细节来自于之前 DeepSeek-V3 的论文。
R1 使用该论文中的基础模型,并仍然经过监督式微调(SFT)和偏好微调步骤,但其执行方式有所不同。
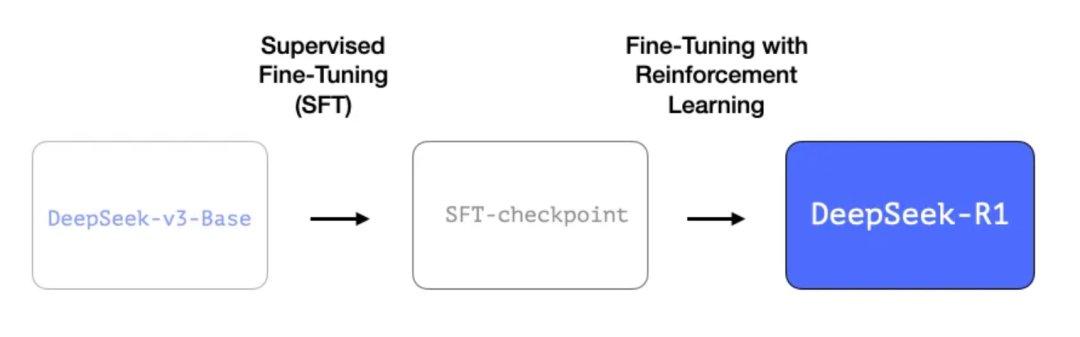
在 R1 的创建过程中,有三点特别值得强调。
这一过程包含 60 万个长思维链推理示例。这些示例非常难以获取,而且人工标注成本非常高。这就是为什么其生成流程成为值得关注的第二大技术亮点。
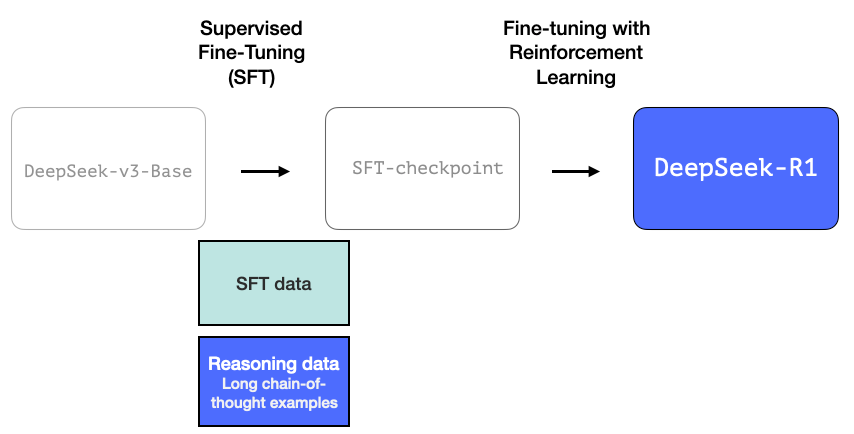
2.阶段性高质量推理大语言模型(但在非推理任务上表现较弱)
该数据由 R1 的前身模型创建——这是一个未命名但专精推理的兄弟模型。该模型的灵感来源于名为 R1-Zero 的第三代模型(后文将详细讨论)。
其重要性不在于作为可直接使用的优质大语言模型,而在于其构建过程仅需极少量的标注数据配合大规模强化学习,最终造就了一个擅长解决推理问题的模型。
通过这个未命名的专业推理模型生成的输出结果,可进一步训练出更通用的模型。这类通用模型在保持其他非推理任务达到用户对大语言模型预期水平的同时,也能完成复杂推理任务。
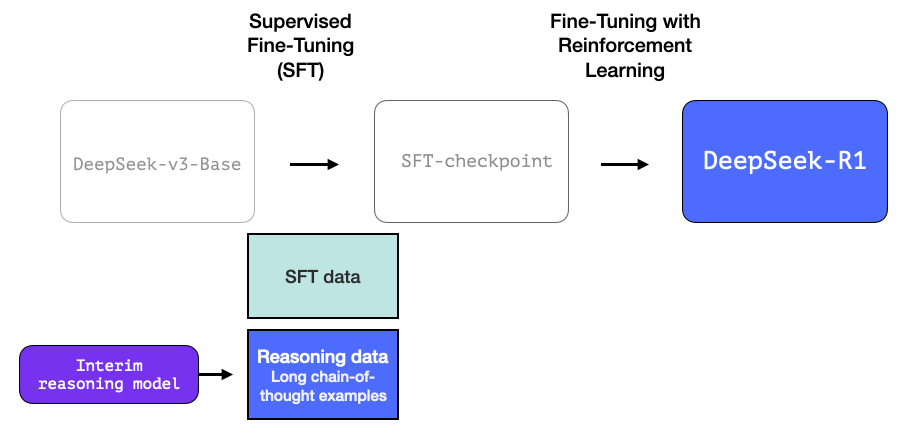
3.运用大规模强化学习(RL)构建推理模型
这一过程分为两步:
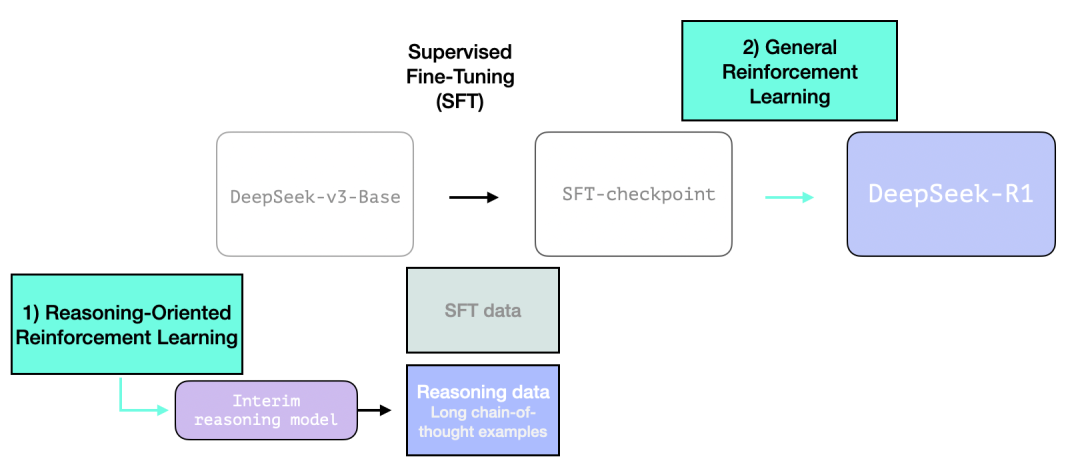
3.1 大规模推理导向强化学习(R1-Zero)
在这里,强化学习(RL)被用来创建一个中间推理模型。该模型随后用于生成监督微调和推理示例。
而使得创建这个模型成为可能的关键在于:该实验创建了一个名为 DeepSeek-R1-Zero 的前身模型。
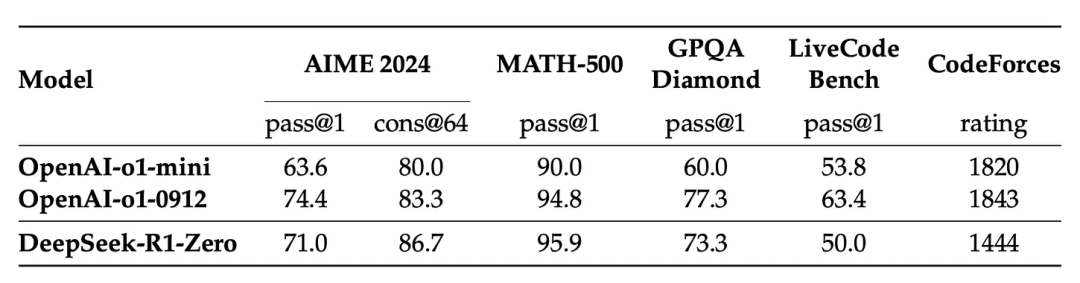
R1-Zero 的特殊之处在于,它无需使用带标签的监督式微调(SFT)训练集,就能在推理任务中表现出色。其训练过程直接从预训练的基础模型开始,通过强化学习(RL)训练流程完成(跳过了 SFT 阶段)。它的表现如此优异,甚至可以与 o1 模型相媲美。
一直以来,数据始终是决定机器学习模型能力的关键要素。那么这个模型是如何打破这一定律的?这涉及两个关键因素:
-
现代基础模型已经达到了质量和能力的阈值(这个基础模型是在 14.8 万亿个高质量 token 上训练的)。
-
与普通的聊天或写作任务不同,推理类问题可通过自动化方式进行验证和标注。让我们通过一个例子来说明。
以下是强化学习(RL)训练步骤中的一个典型提示词:
写一段 Python 代码,接收数字列表并返回排序后的结果,但是需要在列表开头添加数字 42。
像这样的问题适合通过多种方式进行自动验证。假设我们将这个问题提供给正在训练中的模型,它会生成一个答案:
-
代码格式验证:用代码检查工具(linter)来验证这个答案是否为正确的 Python 代码。
-
运行时验证:直接运行 Python 代码,看它是否能正常执行。
-
功能验证:借助现代代码大模型自动生成单元测试(即使这些大模型本身并非推理专家),验证代码是否满足功能要求。
-
性能优化:更进一步,可测量代码执行时间,在训练过程中引导模型优先选择性能更优的解决方案——即使其他方案同样是正确的 Python 程序。
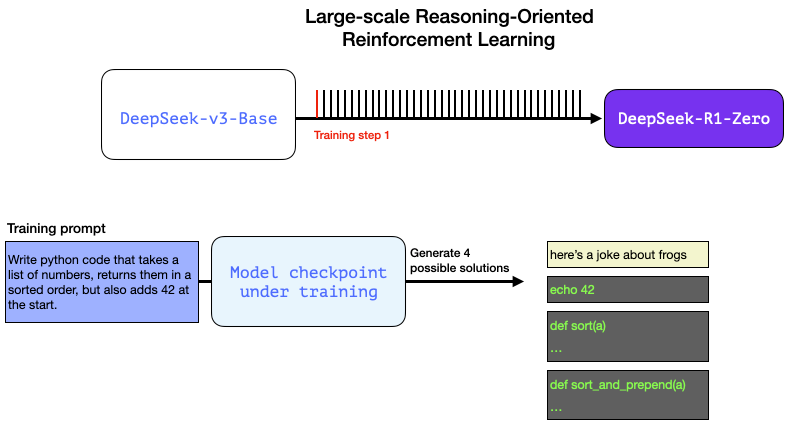
通过自动检查(无需人工干预),我们发现:
-
第一个答案根本不是代码,
-
第二个是代码,但不是 Python 代码,
-
第三个是一个看似可行的解决方案,但没有通过单元测试,
-
第四个才是正确的解决方案。
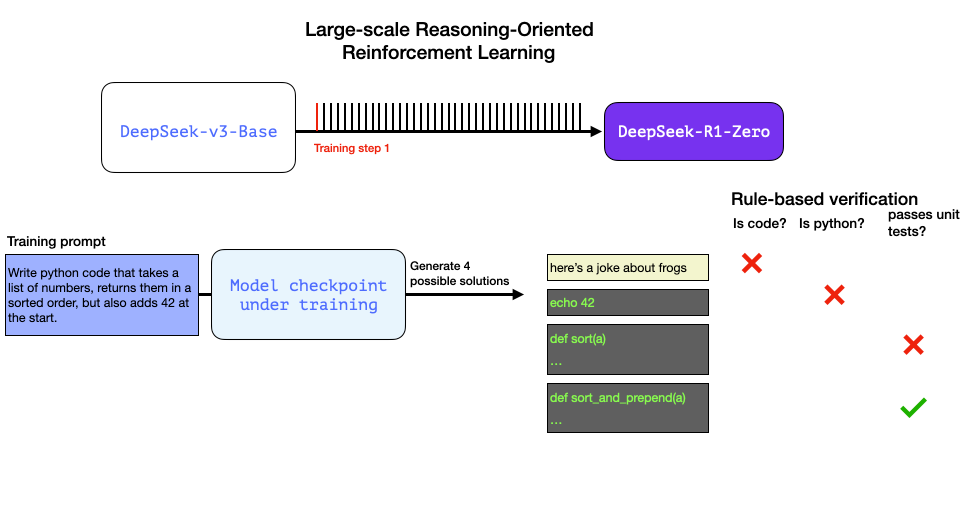
这些自动化生成的训练信号都能直接用于模型优化。这一过程自然需要在小批量样本中处理大量案例,并通过连续训练迭代,逐步优化。
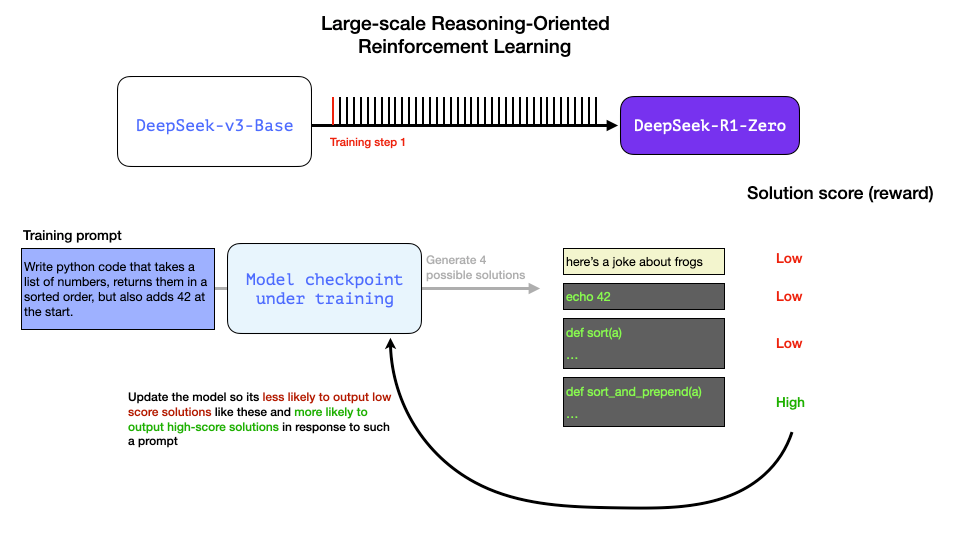
正如论文图 2 所示,在强化学习训练过程中,正是通过这些奖励信号与模型参数更新的动态反馈机制,模型得以在各项任务中持续提升表现。
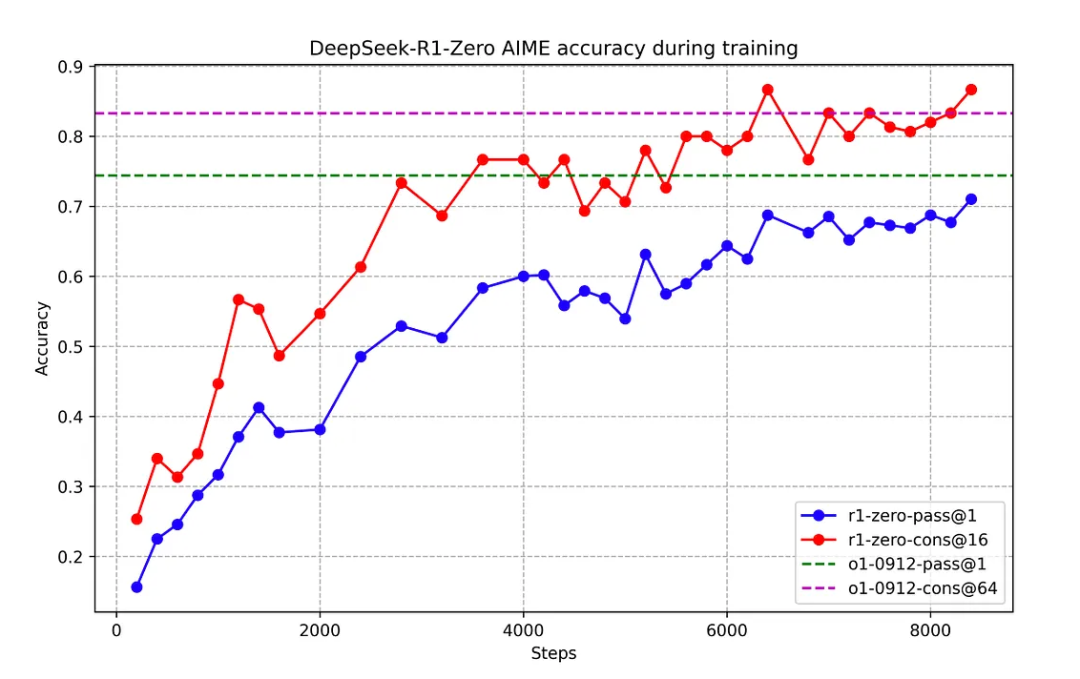
图2:在训练过程中,DeepSeek-R1-Zero 的 AIME 准确率。对于每个问题,我们会采样 16 个响应并计算总体平均准确率,以确保评估的稳定性。
模型能力的提升与生成内容长度的增加呈现对应关系——随着处理问题复杂度的提高,模型会生成更多用于推理的思维标记(thinking tokens)。
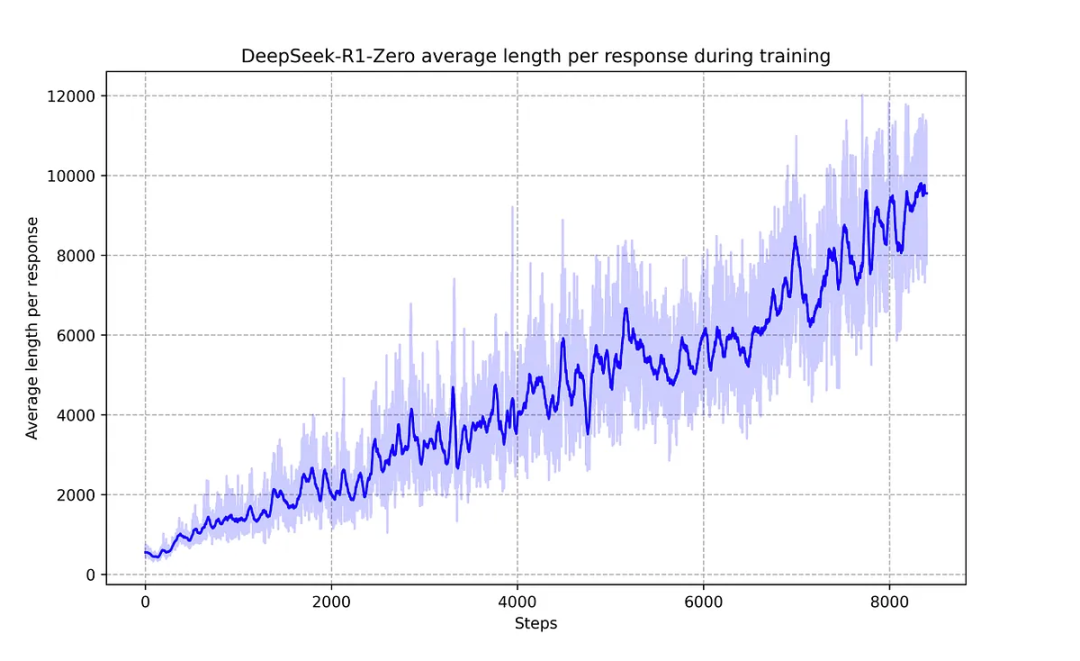
图3:在强化学习过程中,DeepSeek-R1-Zero 在训练集上的平均响应长度。DeepSeek-R1-Zero 自然地学会了通过更多的思考时间来解决推理任务
这个过程是有用的,但尽管 R1-Zero 模型在推理问题上得分很高,它还存在其他缺陷,导致实际可用性不及预期。
尽管 DeepSeek-R1-Zero 展现出强大的推理能力,并能自主地发展出意想不到且强大的推理行为,但它仍然面临一些挑战。例如,DeepSeek-R1-Zero 生成的内容可读性差、语言混杂等问题。
R1 的目标旨在实现更优的实用性。因此,R1 并没有完全依赖强化学习过程,而是在以下两个环节进行了优化(如本节前文所述):
(1)构建中间推理模型来生成监督式微调( SFT )数据点
(2)训练 R1 模型以提升推理和非推理问题的处理能力(使用其他类型的验证器)
3.2 利用中间推理模型创建监督微调(SFT)推理数据
为使中间推理模型更具实用性,需对其进行监督式微调(SFT)训练,训练数据包含数上千个推理问题案例(部分由 R1-Zero 生成并筛选)。论文将此称为“冷启动数据”。
2.3.1 冷启动
与 DeepSeek-R1-Zero 不同,为了避免基础模型在强化学习训练初期出现不稳定的冷启动阶段,我们对 DeepSeek-R1 构建并收集了少量的长思维链(CoT)数据来进行微调模型,将其作为强化学习(RL)的初始执行体。采用长思维链作为示例进行少样本提示学习,直接通过提示词引导模型生成包含反思和验证的详细答案,以可读格式采集 DeepSeek-R1-Zero 的输出,收集 DeepSeek-R1-Zero 的输出并以可读格式呈现,然后通过人工标注者的后处理来优化结果。
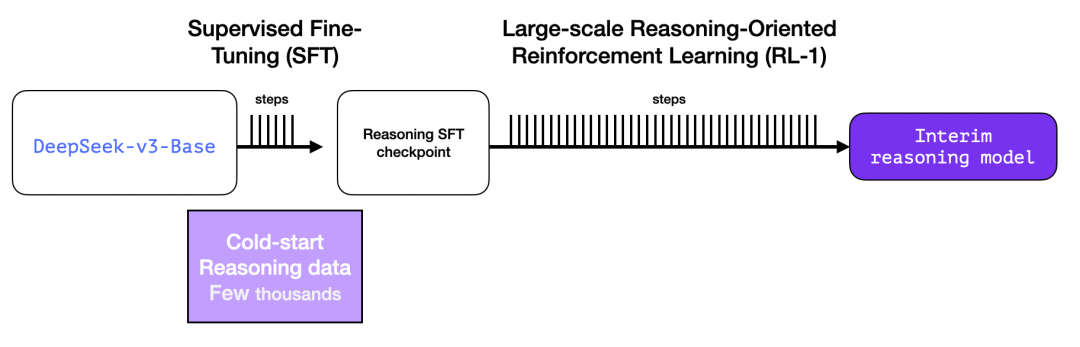
但问题来了——既然已有这类数据,为何仍需依赖强化学习(RL)流程?
核心症结在于数据规模的鸿沟。冷启动数据集可能仅有 5000 个样本(尚可人工收集),但要训练完整的 R1 模型需要 60 万个样本。
中间推理模型正是为了弥合这一差距,通过合成生成海量高价值训练数据而存在。
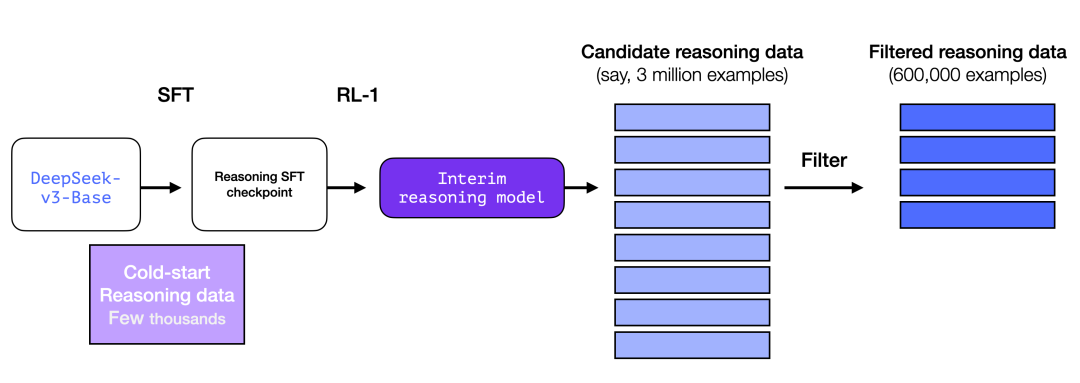
3.3 通用强化学习(RL)训练阶段
这使得 R1 模型不仅在推理任务中表现卓越,还能胜任各类非推理任务。
其训练机制与前述强化学习流程类似,但针对非推理类应用场景进行了扩展优化——通过引入实用性奖励模型与安全性奖励模型(类似Llama模型的机制)对相关应用的提示进行多维评估。
这种复合奖励机制确保模型在扩展应用边界时,既能保持输出有效性,又能遵循安全伦理规范。
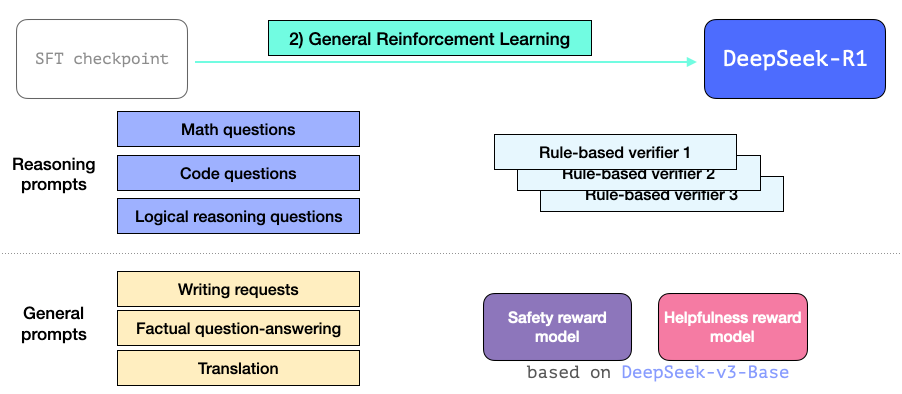
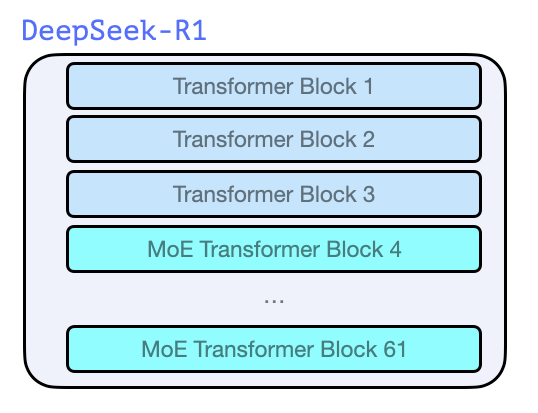
4.架构
DeepSeek-R1 沿袭了 GPT-2、GPT-3 等经典模型的架构范式,基于 Transformer 解码器模块堆叠构建。其结构特性如下:
-
总层数:共包含 61 层 Transformer 解码器模块
-
底层结构:前 3 层为密集全连接层(Dense Layers)
-
高层优化:剩余 58 层采用专家混合架构( Mixture of Experts, MoE)关于 MoE 的直观解析,可参阅“袋鼠书”另一个作者 Maarten 的权威指南:混合专家模型(MoE)视觉化指南 )
这种分层设计融合了基础模型的稳定性和 MoE 架构的高效性,在保证推理能力的同时显著提升计算资源利用率。
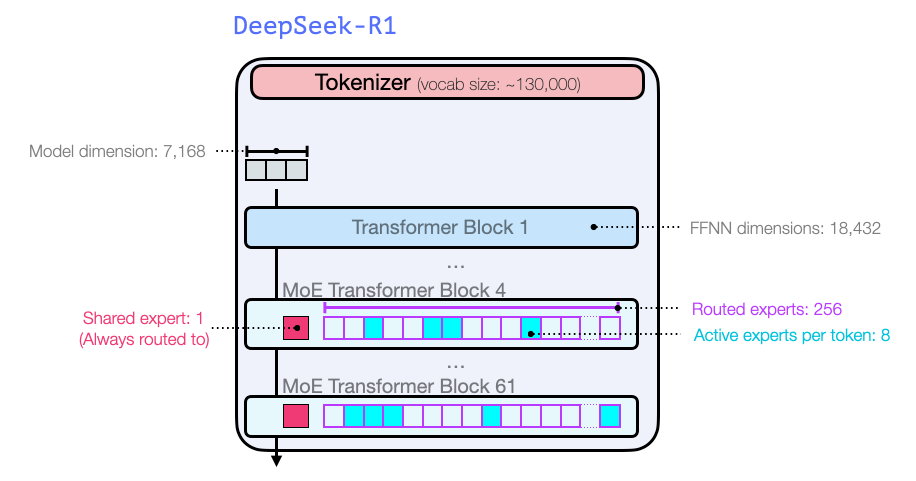
关于模型维度大小和其他参数方面,它们如下所示:
结论通过这些内容,你应该对 DeepSeek-R1 模型有了一个直观的理解。

美亚 4.7 星评,畅销书 Hands-on 系列新作。只要具备 Python 基础,就可以通过本书学习大语言模型,并将大语言模型的能力应用到真正的 AI 实践中。
本书将为 Python 开发人员提供使用大模型的实用工具和概念,帮助大家掌握实际应用场景。你将学习如何利用预训练的大型语言模型进行文案撰写、文本摘要、语义搜索等任务,构建超越关键词匹配的智能系统。
扫码啦!一起进群学习~👇
