Meta新型记忆层显著提升LLM性能,1280亿参数规模下超越更大规模密集模型和MoE模型。
原文标题:Meta探索大模型记忆层,扩展至1280亿个参数,优于MoE
原文作者:机器之心
冷月清谈:
Meta 的研究人员探索了一种新型记忆层,可以增强大型语言模型(LLM)的性能。通过将记忆层集成到 transformer 模型中,即使参数规模不变,模型的性能也能显著提升。
该记忆层使用可训练的键值查找机制,类似于注意力机制,但键和值是可训练的参数。研究人员通过并行化嵌入查找和聚合、共享记忆参数池以及引入输入相关门控等技术对记忆层进行了扩展和优化。
实验结果表明,在各种基准测试中,具有记忆层的模型在性能上优于参数规模更大的密集模型以及计算和参数规模相当的专家混合(MoE)模型。例如,一个 13 亿参数且包含 6400 万键(1280 亿记忆参数)的记忆模型的性能接近于 70 亿参数的 Llama2 模型,而后者的计算量是前者的 10 倍以上。这表明,记忆层为 LLM 的扩展提供了一条高效且高性能的途径。
该记忆层使用可训练的键值查找机制,类似于注意力机制,但键和值是可训练的参数。研究人员通过并行化嵌入查找和聚合、共享记忆参数池以及引入输入相关门控等技术对记忆层进行了扩展和优化。
实验结果表明,在各种基准测试中,具有记忆层的模型在性能上优于参数规模更大的密集模型以及计算和参数规模相当的专家混合(MoE)模型。例如,一个 13 亿参数且包含 6400 万键(1280 亿记忆参数)的记忆模型的性能接近于 70 亿参数的 Llama2 模型,而后者的计算量是前者的 10 倍以上。这表明,记忆层为 LLM 的扩展提供了一条高效且高性能的途径。
怜星夜思:
1、文章中提到记忆层的键值查找机制类似于注意力机制,但键和值是可训练的参数。这种设计相比传统的注意力机制有什么优势和劣势呢?
2、文章提到了并行记忆、共享记忆等技术,这些技术是如何解决记忆层扩展带来的挑战的?有没有其他潜在的优化方向?
3、记忆层在LLM扩展中展现了巨大的潜力,但它是否会取代传统的参数扩展方式?未来LLM的架构会如何发展?
2、文章提到了并行记忆、共享记忆等技术,这些技术是如何解决记忆层扩展带来的挑战的?有没有其他潜在的优化方向?
3、记忆层在LLM扩展中展现了巨大的潜力,但它是否会取代传统的参数扩展方式?未来LLM的架构会如何发展?
原文内容
机器之心报道
编辑:小舟、陈陈
预训练语言模型通常在其参数中编码大量信息,并且随着规模的增加,它们可以更准确地回忆和使用这些信息。对于主要将信息编码为线性矩阵变换权重的密集深度神经网络来说,参数大小的扩展直接与计算和能量需求的增加相关。语言模型需要学习的一个重要信息子集是简单关联。虽然前馈网络原则上(给定足够的规模)可以学习任何函数,但使用联想记忆(associative memory)会更高效。
记忆层(memory layers)使用可训练的键值查找机制向模型添加额外的参数,而不会增加 FLOP。从概念上讲,稀疏激活的记忆层补充了计算量大的密集前馈层,提供了廉价地存储和检索信息的专用容量。
最近,Meta 的一项新研究使记忆层超越了概念验证,证明了它们在大型语言模型(LLM)扩展中的实用性。

-
论文标题:Memory Layers at Scale
-
论文地址:https://arxiv.org/pdf/2412.09764
-
项目地址:https://github.com/facebookresearch/memory
在下游任务中,通过改进的记忆层增强的语言模型的性能优于计算预算两倍以上的密集模型,以及在计算和参数相当的专家混合(MoE)模型。
这项工作表明,当记忆层得到充分改进和扩展时,可以用于增强密集神经网络,从而带来巨大的性能提升。通过用记忆层替换一个或多个 transformer 层的前馈网络(FFN)来实现这一点(保持其他层不变)。这些优势在各种基本模型大小(从 1.34 亿到 80 亿参数)和内存容量(最多 1280 亿参数)中都是一致的。这意味着存储容量实现了两个数量级的飞跃。
记忆增强架构
可训练的记忆层类似于注意力机制。给定一个查询 ,一组键
,一组键 ,以及值
,以及值 。输出是值的软组合,根据 q 和相应键之间的相似性进行加权。
。输出是值的软组合,根据 q 和相应键之间的相似性进行加权。
在使用时,记忆层与注意力层之间存在两个区别。
-
首先,记忆层中的键和值是可训练参数,而不是激活参数;
-
其次,记忆层在键和值的数量方面通常具有更大的规模,因此稀疏查询和更新是必需的。
该研究将键-值对的数量扩展到数百万。在这种情况下,只有 top-k 最相似的键和相应的值被输出。一个简单的记忆层可以用下面的等式来描述:
其中,I 是一组指标,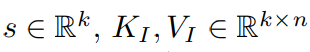 ,输出
,输出 。
。
,输出
扩展记忆层
扩展记忆层时面临的一个瓶颈是「查询 - 键」检索机制。简单的最近邻搜索需要比较每一对查询 - 键,这对于大型记忆来说很快就变得不可行。虽然可以使用近似向量相似性技术,但当键正在不断训练并需要重新索引时,将它们整合起来是一个挑战。相反,本文采用了可训练的「product-quantized」键。
并行记忆。记忆层是记忆密集型的,主要是由于可训练参数和相关优化器状态的数量庞大导致的。该研究在多个 GPU 上并行化嵌入查找和聚合,记忆值在嵌入维度上进行分片。在每个步骤中,索引都从进程组中收集,每个 worker 进行查找,然后将嵌入的部分聚合到分片中。此后,每个 worker 收集与其自身索引部分相对应的部分嵌入。该过程如图 2 所示。
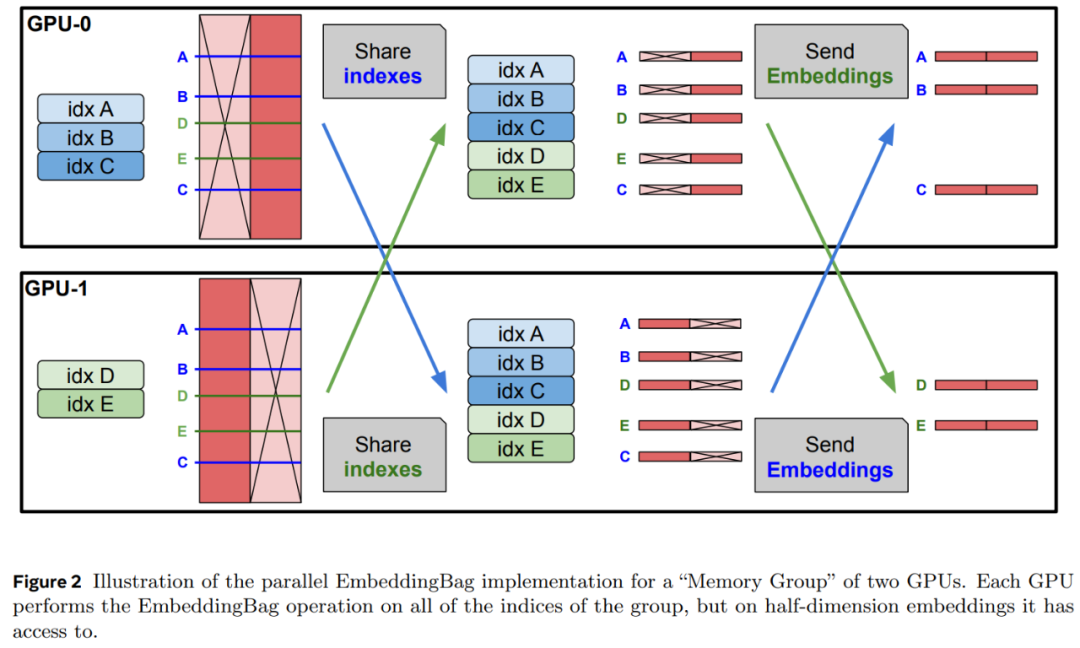
共享记忆。深度网络在不同层上以不同的抽象级别对信息进行编码。向多个层添加记忆可能有助于模型以更通用的方式使用其记忆。与以前的工作相比,该研究在所有记忆层中使用共享记忆参数池,从而保持参数数量相同并最大化参数共享。
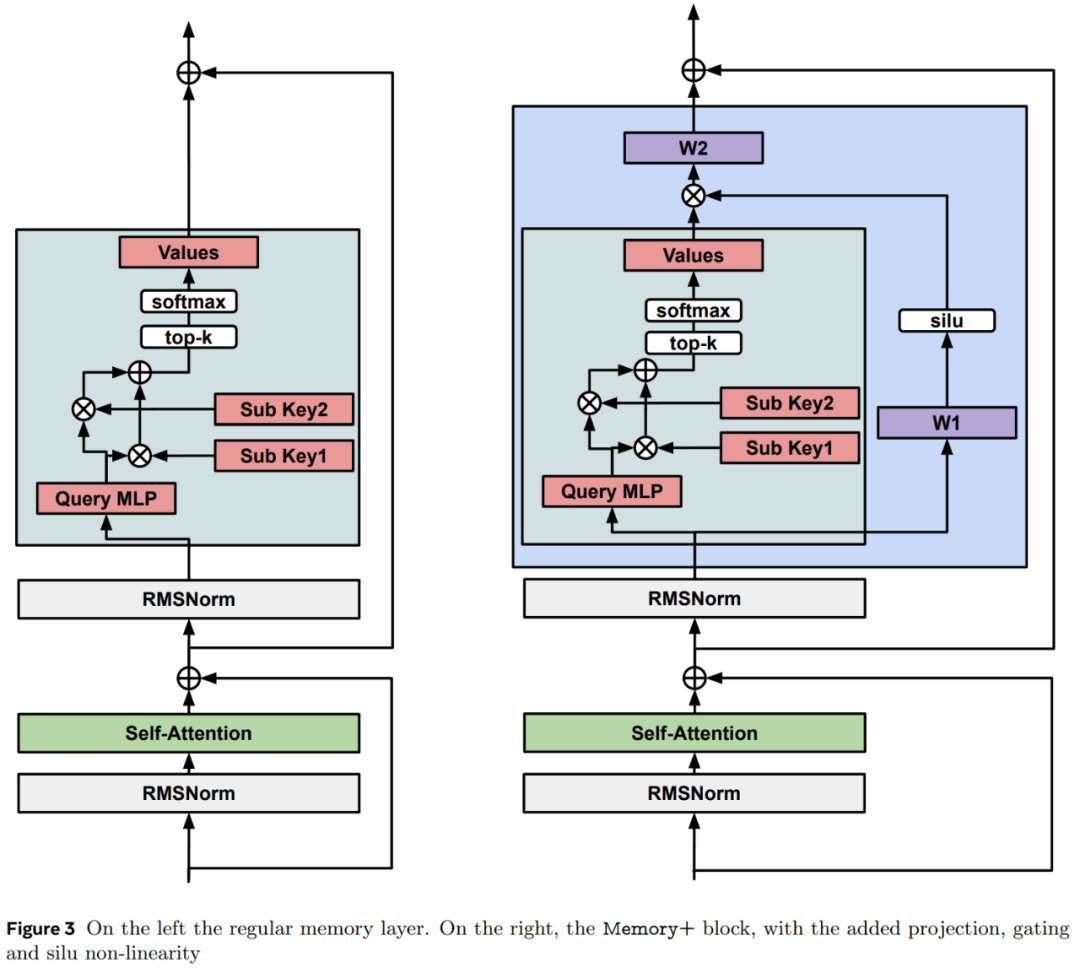
该研究通过引入具有 silu 非线性的输入相关门控来提高记忆层的训练性能。等式 (1) 中的输出变为:
其中 silu (x) = x sigmoid (x),⊙是元素的乘法(参见图 3)。
实验及结果
首先,该研究固定记忆大小,并与密集基线以及参数大致匹配的 MOE 和 PEER 模型进行比较。
从表 1 中我们可以看出,Memory 模型比密集基线模型有了大幅改进,在 QA 任务上的表现通常与密集参数数量为其两倍的模型相当。
Memory+ (有 3 个记忆层)比 Memory 有了进一步的改进,其性能通常介于计算能力高出其 2 到 4 倍的密集模型之间。
对于相同数量的参数,PEER 架构的表现与 Memory 模型相似,但落后于 Memory+。MOE 模型的表现远不及 Memory 变体。
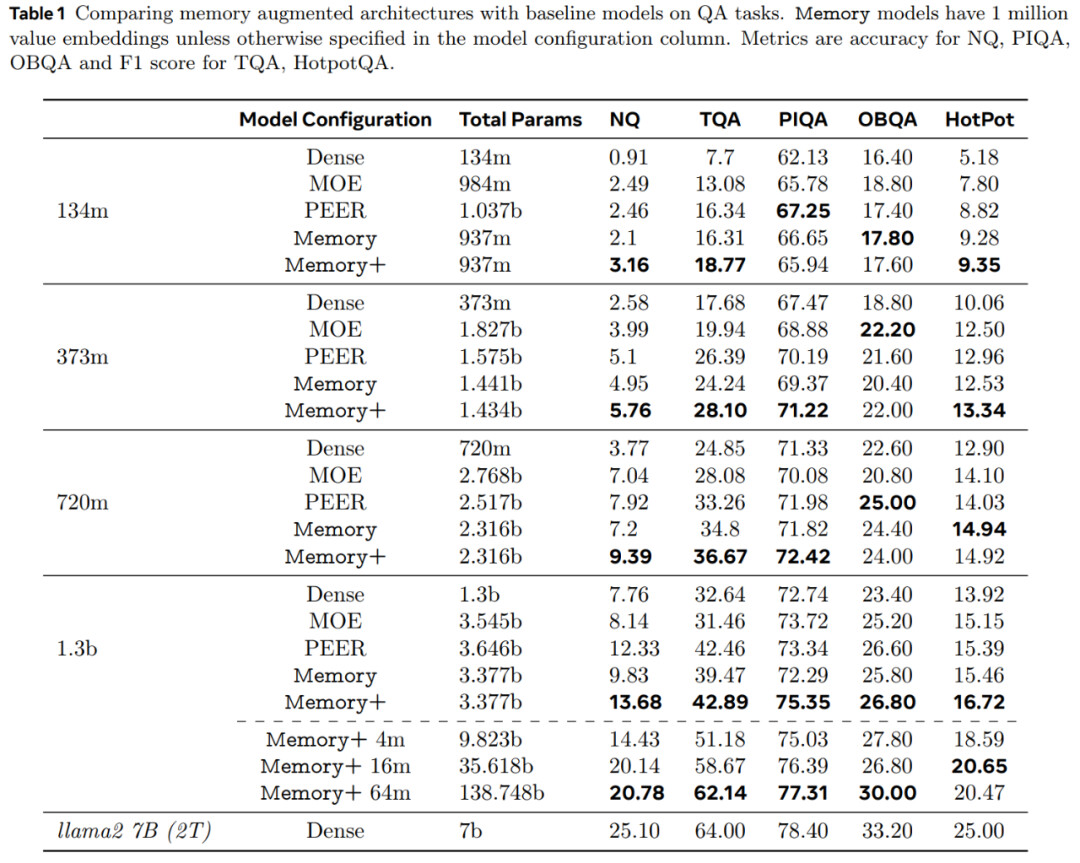
图 4 显示了不同大小的 Memory、MOE 和密集模型在 QA 任务上的扩展性能。
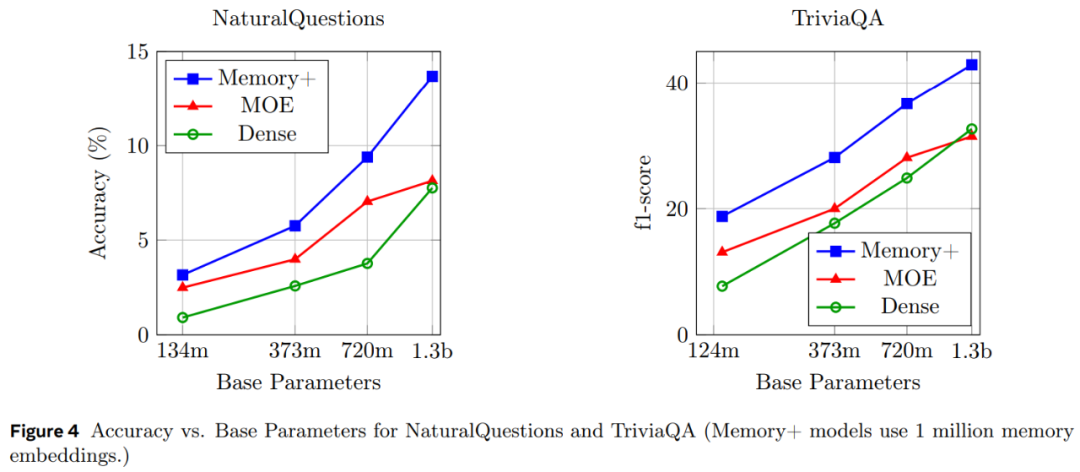
图 1 表明 Memory+ 模型的实际 QA 性能随着记忆大小的增加而不断的增加。
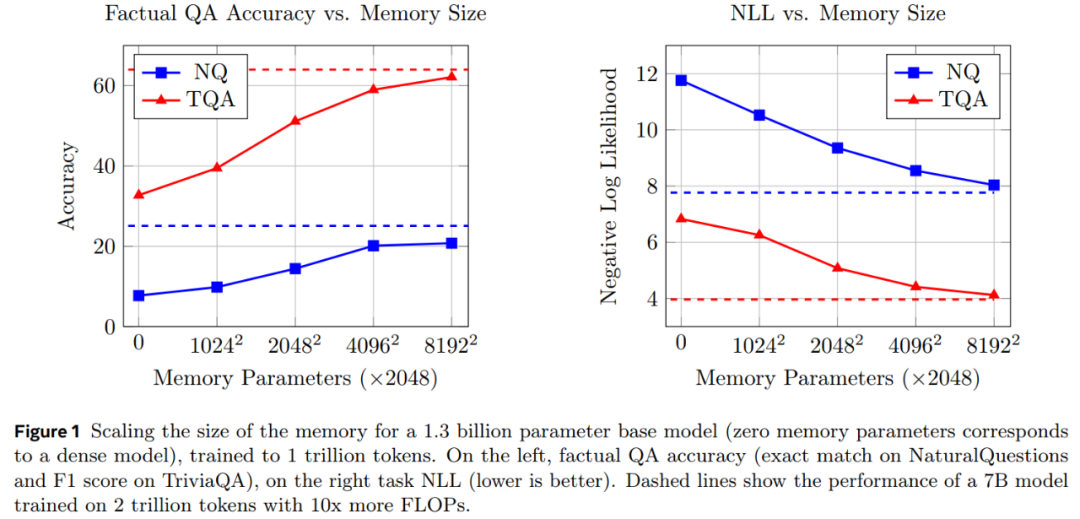
在 6400 万个键(1280 亿个记忆参数)下,1.3B Memory 模型的性能接近 Llama2 7B 模型,后者使用了 10 倍以上的 FLOPs(见表 2)。
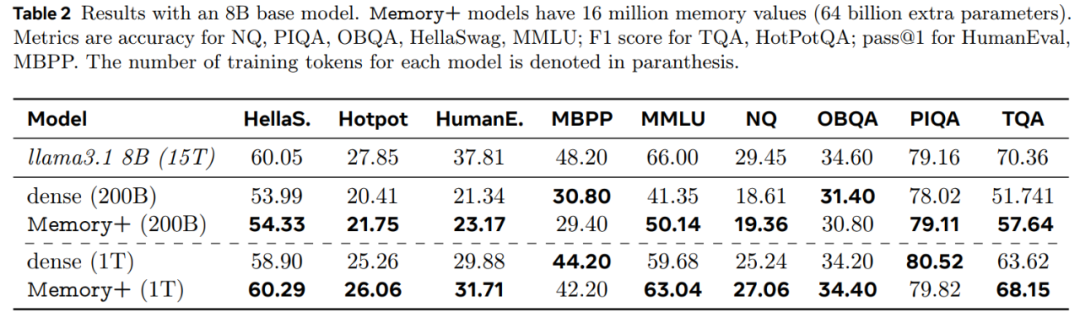
最后,本文在 8B 基础模型和 4096^2 个记忆值的基础上 (64B 记忆参数)扩展了 Memory+ 模型,表 2 报告了结果,发现记忆增强模型的表现明显优于密集基线。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com