PAT3D把物理仿真引入文生3D,让生成场景不仅能看,还更稳定、可编辑、可交互。
原文标题:ICLR 2026|CMU等团队让AI生成的3D场景真正「站得住」:PAT3D把文生3D从能看推进到能模拟、能交互
原文作者:机器之心
冷月清谈:
PAT3D 的核心流程分为三步:先根据文本生成参考图,并借助视觉语言模型抽取物体类别、材质和相对关系,为每个对象单独生成3D资产;再通过深度估计和“场景树”构建粗略3D布局,对物体间的重叠和沿重力方向的关系做初步修正;最后结合可微刚体仿真进行闭环优化,让场景在满足支撑、包含等语义关系的同时,达到物理稳定。
实验显示,PAT3D 在复杂提示词测试中相比 GraphDreamer、Blender-MCP、MIDI 等方法,物理合理性更强,继续模拟位移和穿插比例都做到 0,物理合理性评分达到 88.5。它的价值不只在论文演示效果,而在于生成结果可直接用于场景编辑、动画制作和机器人仿真。论文已被 ICLR 2026 接收,项目与代码也已公开,体现出“物理增强”可能成为文生3D走向实用化的重要方向。
怜星夜思:
2、PAT3D里用了“场景树”去表达支撑、包含这类关系。你觉得这种结构化关系,未来会不会比单纯堆更大的生成模型更重要?
3、文章里提到 PAT3D 能直接服务动画制作和机器人仿真。你觉得离真正大规模落地,还差哪些关键环节?
4、如果以后这类“物理增强”的文生3D成熟了,你最先想到会改变哪个行业的工作方式?为什么?
原文内容

论文已被 ICLR 2026 接收,第一作者为 CMU 博士生林谷颖,师从 CMU 的李旻辰教授。研究团队中还包括 CMU 的 Jun-Yan Zhu 教授、Michael Liu、高睿晗、陈瀚可、陈律豪、卢贝嘉、HKU 的 Taku Komura 教授、黄可蒙,以及 HKUST 的刘缘教授。
现在的 3D AIGC 已经可以很快生成场景,但离真正落地还有一段距离。很多场景看起来还行,一进物理模拟就会暴露问题,比如物体悬空、互相穿插,甚至还没碰就散。这些问题让它们很难直接用于游戏、XR 或机器人等实际场景。
问题的根源在于,过去的大多数文生 3D 方法主要优化的是视觉效果:只要渲染出来看起来合理就可以。但这种做法忽略了一个关键点——场景是否在物理上成立。一旦进入模拟环境,物体之间的接触、支撑关系以及整体稳定性都会成为问题,而这些恰恰是实际应用中最关键的部分。
来自卡耐基梅隆大学(CMU)、香港大学(HKU)和香港科技大学(HKUST)的研究团队提出了 PAT3D(Physics-Augmented Text-to-3D Scene Generation),尝试解决这个问题。他们的目标很直接:让生成的 3D 场景不只是视觉上合理,而是在物理上也站得住,可以直接用于编辑、交互和仿真。

图 1:PAT3D 关注的不只是视觉效果,而是让场景在模拟中也能成立。

-
论文标题:PAT3D: Physics-Augmented Text-to-3D Scene Generation
-
论文地址:https://openreview.net/pdf?id=iIRxFkeCuY
-
论文作者:Guying Lin, Kemeng Huang, Michael Liu, Ruihan Gao, Hanke Chen, Lyuhao Chen, Beijia Lu, Taku Komura, Yuan Liu, Jun-Yan Zhu, Minchen Li
-
作者单位:卡耐基梅隆大学、香港大学、香港科技大学
-
项目主页: https://simulation-intelligence.github.io/PAT3D/
-
代码链接: https://github.com/Simulation-Intelligence/PAT3D
PAT3D 是怎么做的?
PAT3D 的思路可以概括成三步。
第一阶段是3D 物体与空间关系抽取。 系统先根据文本提示生成一张参考图,再借助视觉语言模型识别场景中的物体类别、材质和相对位置,并把图像分割成多个对象区域。随后,系统为每个对象分别生成 3D 资产,而不是把整个场景直接做成一个整体网格。这样做的关键意义在于:后续每个物体都能作为独立刚体参与接触、碰撞和支撑关系计算。
第二阶段是布局初始化。 PAT3D 会先利用单目深度估计,把 2D 参考图回投成粗略的 3D 布局,再根据视觉语言模型抽取出的物体依赖关系,构建一个层级化的「场景树」。这个「场景树」描述的不是普通语义标签,而是沿重力方向的物理依赖,例如「支撑」「包含」等。在此基础上,PAT3D 会对初始布局做两类修正:
一类是同层物体之间的水平去重叠,避免兄弟节点互相挤压;另一类是父子节点之间沿重力方向的垂直分离,例如让「杯子里的笔」先处在合理的容器范围内、让「桌上的书」先位于桌面的支撑区域之上。这样得到的初始化场景,不一定已经完全稳定,但至少是无穿插、适合进入物理模拟的。
第三阶段是布局优化。 PAT3D 引入了 libuipc 的可微刚体仿真,让物体在重力和接触力作用下朝静力平衡状态演化。这里更关键的一点是,它并不满足于「只要物理上站得住就行」。因为单靠物理仿真,很多场景虽然稳定,却可能偏离文本语义,比如本应放在桌上的物体滑落到地面,依然可能是一个物理上成立的终态。
为了解决这个问题,PAT3D 引入了基于物理模拟的闭环优化:它根据最终模拟状态是否满足「场景树」中的包含与支撑关系,定义语义损失,再把这个损失反向传回初始布局,持续调整初始位置。这样,最终得到的不是单纯「不会倒」的场景,而是「既稳定、又尽量保留文本语义」的场景。
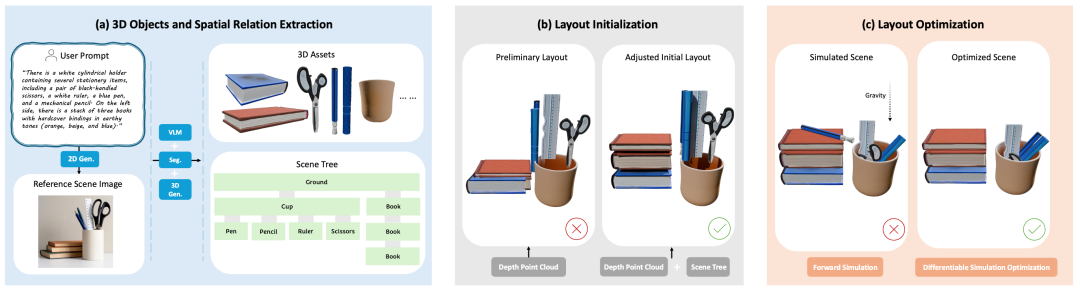
图 2:PAT3D 将物体生成、关系理解、布局初始化和物理优化串联成一个完整流程。
下面的视频展示了一个具体示例的生成过程。
实验结果说明了什么?
从结果看,PAT3D 的优势并不只是「更稳定一点」,而是把场景生成从「能展示」推到了「能落地」。在包含 18 个复杂提示词的测试中,PAT3D 与 GraphDreamer、Blender-MCP、MIDI 等方法进行了比较。结果显示,PAT3D 在关键物理指标上非常突出:继续模拟位移为 0,物体穿插比例为 0,物理合理性评分高达 88.5。
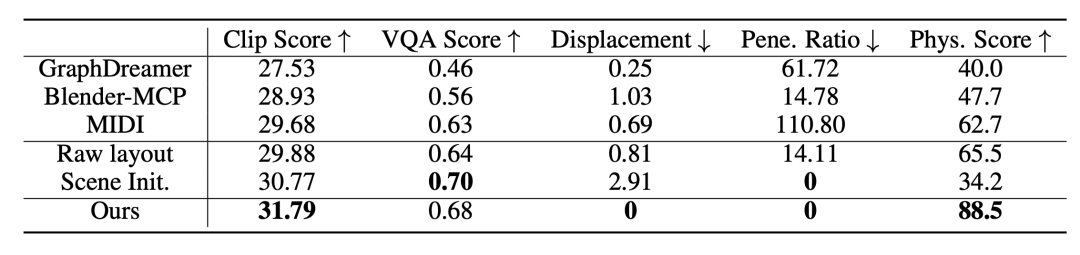
图 3:PAT3D 与现有方法在场景质量和物理合理性上的定量对比。
更直观地看,在书本、杯子、餐具、积木、水果篮这些接触关系比较复杂的场景里,PAT3D 能避免物体悬空和模拟后坍塌,并且明显减少摆放错位。以积木堆叠为例,普通方法生成的布局往往要么不符合物理规律,要么一进入模拟就容易倒掉;而 PAT3D 会进一步调整初始摆放,使最终稳定下来的结果仍然尽量贴近文本描述。

图 4:与已有方法相比,PAT3D 在复杂接触场景里更容易得到物理合理的结果。
为什么这项工作值得关注?
更重要的是,PAT3D 的结果不是停留在论文图里的静态展示,而是可以直接拿去做后续任务。论文里展示了三个很有代表性的应用方向。
第一个是场景编辑。 当用户删除一个笔筒、抽走一本书,或在原有布局上再加一个物体时,场景不会立刻变成一团穿插或悬空的模型,而是能在模拟中重新达到平衡。这意味着未来的 3D 内容创作可以更像「搭积木」。

图 5:PAT3D 支持增删物体后的物理一致场景编辑。注:此处仿真为准静态。
第二个是动画制作。 PAT3D 生成的场景本身就满足基本的物理约束,因此不需要再花很多时间手动修正和调整初始布局,就可以直接用于后续动画制作。换句话说,它生成的不只是一个静态场景,而是一个已经为运动和模拟做好准备的场景。在传统的物理仿真动画制作中,场景建模上往往需要花费大量时间,PAT3D 无疑将大大提高其效率。

图 6:PAT3D 生成的场景可直接用于后续动画制作。
第三个是机器人仿真。 机器人通常需要靠模拟环境检验学习到的抓取、搬运和交互策略。如果场景本身存在漂浮、重叠或碰撞不合理等问题,那么训练出来的结果往往也不可靠。PAT3D 生成的场景可以直接导入模拟器,用来测试抓取是否成功、操作过程中物体会不会倾倒,从而为机器人训练和评估提供大量更可信的环境。

图 7:当生成的场景能够直接进入机器人模拟流程,文本到场景的价值就不再只是展示。左图展示了成功抓取的例子,右图展示了失败抓取的例子。
PAT3D 的意义,不只是让生成结果更好看,而是让 3D 生成更接近真正可用。随着生成系统开始同时理解和处理语义、结构与物理,它面向的也不再只是展示层面的效果,而是更完整的数字内容生产流程,以及机器人、仿真等更真实的应用场景。
同时,PAT3D 的成功也让我们看到将物理仿真用于 3D 生成任务的巨大潜力。更可贵的是,其源代码已在 Apache-2.0 许可下开源,这不仅降低了研究复现与二次开发的门槛,也为社区进一步验证、扩展和落地这一路线提供了坚实基础。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com