PixelRefer:AI从“看大图”走向“看懂每个对象”。浙大等提出,通过SAOT和OCI实现像素级细粒度视觉理解,推理速度提升4倍,显存减半,引领AI迈向更精细的动态世界感知。
原文标题:PixelRefer :让AI从“看大图”走向“看懂每个对象”
原文作者:机器之心
冷月清谈:
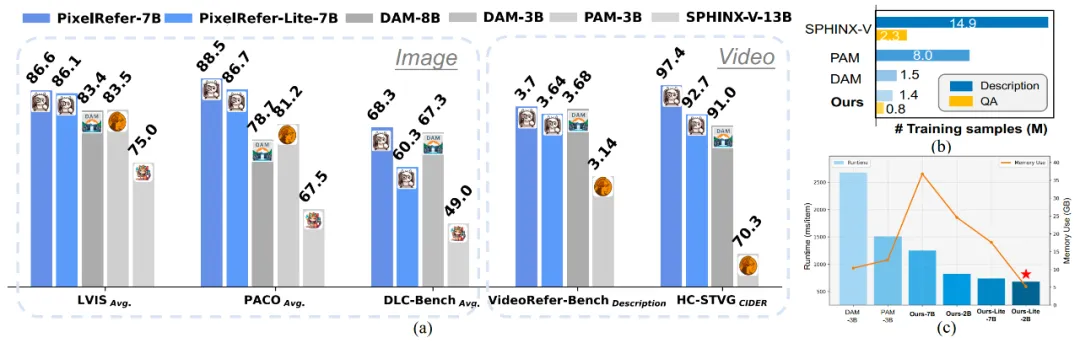
为解决这一挑战,浙江大学、达摩院和香港理工大学联合推出了 **PixelRefer**,这是一个创新的统一时空像素级区域理解框架。该框架能够实现任意粒度下的精细视觉指代与推理,并在多项像素级细粒度理解任务中取得了领先性能。与DAM-3B相比,轻量级的PixelRefer-Lite 2B模型在推理时间上加快了4倍,显存占用减半,同时所需的训练数据量也远少于现有方法。
PixelRefer的核心突破在于对大模型“如何看懂区域”的深度探索。研究发现,像素级区域token在LLM的深层回答中扮演着关键角色,而全局图像token在深层则显得冗余。基于此,团队提出了两种设计方案:PixelRefer(Vision-Object Framework)和PixelRefer-Lite(Object-Only Framework)。
PixelRefer框架将全局视觉token、像素级区域token和文本token一同输入LLM,力求在保留场景语境的同时,实现对象级的精细推理。其关键在于引入了尺度自适应对象分词器(SAOT),该分词器能够动态处理不同大小的目标,通过位置感知的掩码特征抽取和冗余聚合,生成精确、紧凑且语义丰富的对象表示。
PixelRefer-Lite 则是更高效的变体,它仅使用对象标记进行LLM推理。通过对象中心信息融合模块(OCI),PixelRefer-Lite 在前处理阶段便将全局特征融入对象表示中,使目标表征同时具备细节感知与全局语义,从而在推理阶段无需再使用全局视觉标记,显著降低了计算开销,同时保持了高精度。
该研究团队还开源了140万样本的Foundational Object Perception和80万样本的Visual Instruction Tuning数据集。实验结果表明,PixelRefer在图像和视频的像素级细粒度理解任务上都达到了SOTA水平,尤其在推理场景和效率方面表现突出。PixelRefer的出现,标志着AI视觉理解正从宏观场景迈向对世界细节和动态的深度理解,为自动驾驶、医疗影像、智能视频监控以及多模态人机交互等领域开启了新的应用前景。
怜星夜思:
2、提升了AI对细节的理解能力,尤其能进行细粒度、对象级的识别与推理,这会不会带来一些新的隐私或伦理问题?比如监控摄像头能精准识别每个人的物品、行为模式,甚至对潜在意图进行推理,我们该如何权衡技术发展与个人隐私保护?
3、PixelRefer主要是在解决区域理解的精确性和效率问题。未来要实现真正通用的“理解世界动态”的视觉智能,除了这些,大家觉得还需要解决哪些更深层次的技术挑战?比如,如何更好地融合人类的常识知识进去?
原文内容

多模态大模型(MLLMs)虽然在图像理解、视频分析上表现出色,但多停留在整体场景级理解。
而场景级理解 ≠ 视觉理解的终点,现实任务(如自动驾驶、机器人、医疗影像、视频分析)需要的是细粒度、对象级(object-level)详细理解。
然而,当下的研究工作,如英伟达的Describe Anything Model (DAM)局限于单个物体的描述,难以深入理解多对象属性、交互关系及其时序演变,且牺牲了模型本身的通用理解能力。
针对这一问题,浙江大学、达摩院、香港理工大学联合提出了一种创新的解决方案PixelRefer:一个统一的时空像素级区域级理解框架,可实现任意粒度下的精细视觉指代与推理,在多项像素级细粒度理解任务取得领先性能表现。和DAM-3B相比,轻量版的2B模型推理时间加快了4倍,显存占用减半,且训练数据量大大少于已有方法。
PixelRefer能够对任意目标实现准确语义理解以及时空物体区域理解。

|

|


-
论文标题:
PixelRefer: A Unified Framework for Spatio-Temporal Object Referring with Arbitrary Granularity
-
论文链接:
https://arxiv.org/abs/2510.23603
-
项目网站链接:
https://circleradon.github.io/PixelRefer/
-
代码链接:
https://github.com/DAMO-NLP-SG/PixelRefer
先验分析:大模型“如何看懂区域”?
为了探索解决以上问题,作者基于通用视觉基础模型采用最直接的设计:将全局视觉token+像素级区域token+文本token一起喂给 LLM。当无物体指代区域时,模型则退化成通用视觉理解任务,从而实现区域理解的同时,保留通用模型本身的通用理解能力。
作者对LLM内从浅层到深层中分析视觉token、区域token以及其他类型token进行可视化分析。本文可以发现从浅层到深层,答案(Ans)优先关注像素级区域token,其attention分数一直很高,说明物体token表征对于模型的回答起到重要的作用。此外,全局图像token(vision)则仅在浅层中(第一层)表现出较高的attention分布(Answer-to-image token attention),LLM的深层则表现较弱,甚至没有影响,这个在通用视觉基础模型研究中也被讨论到。
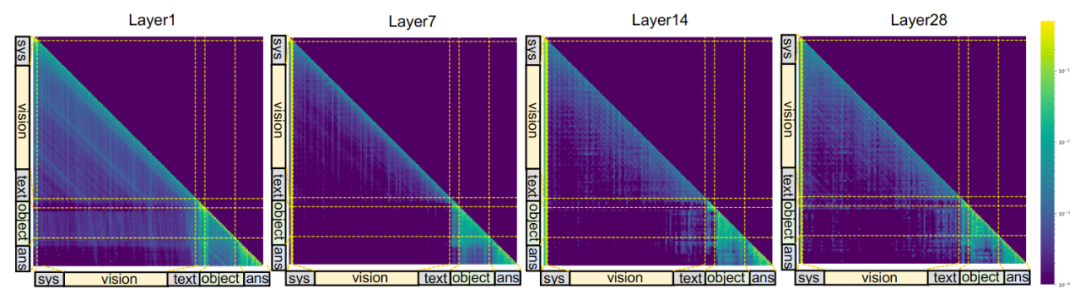
浅层到深层的attention可视化
基于此分析,作者得出两种设计方案:
-
高质量像素级物体表征很重要:对于像素级区域的表达,语义丰富的区域表征直接决定像素级语义理解的质量;
-
全局信息的冗余可以通过“预融合”优化 :在 LLM 深层阶段,全局视觉标记的作用显著减弱,在深层阶段反而变得冗余,说明其信息可提前注入对象标记中,以大幅减少计算开销。
方法设计
为此,作者针对像素级细粒度理解定义了两种框架,Vision-Object Framework (a)与Object-Only Framework (b):
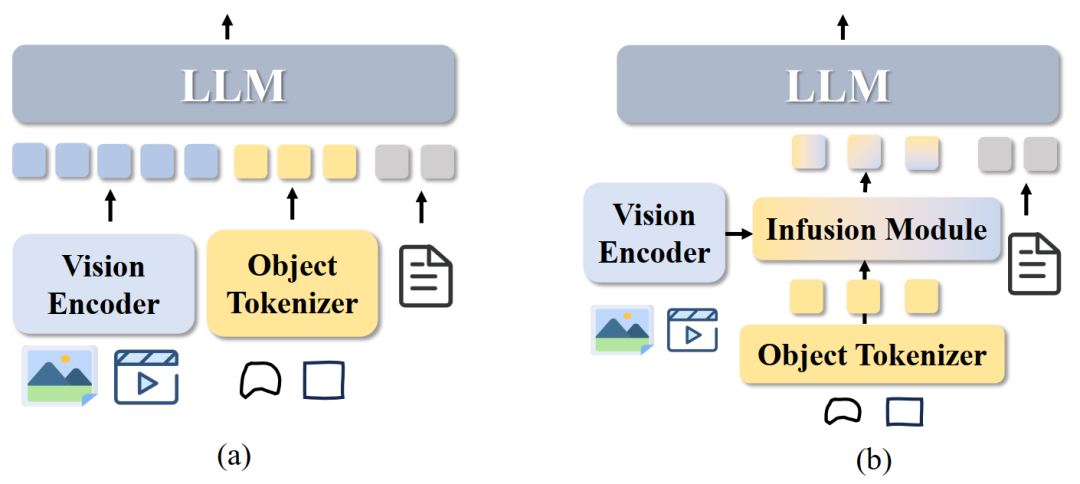
PixelRefer(Vision-Object Framework)
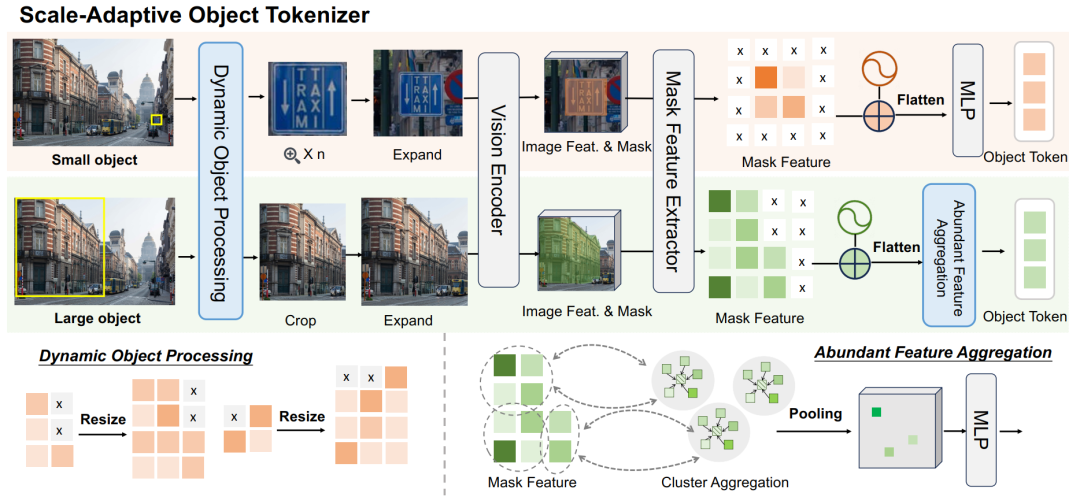
对于PixelRefer,作者把全局视觉token+像素级区域token+文本token一起送入 LLM,既保留场景语境,又在对象级上精细推理。关键在于像素级区域表征token质量足够高。为此,作者提出尺度自适应对象分词器(Scale-Adaptive Object Tokenizer, SAOT) 来生成精确、紧凑、语义丰富的对象表示。
SAOT 围绕两个设计:(i)小目标容易在patch化后丢失细节;(ii)大目标的特征冗余严重。
核心做法分三步:
-
动态尺度处理(Dynamic Object Processing)。按像素级区域大小自适应地放大小物体、缩小大物体,并进行上下文扩展(在目标周围留出一定背景),保证既不丢细节也不过度冗余。随后通过共享视觉编码器取到区域级特征。
-
位置感知的掩码特征抽取(Mask Feature + Relative Positional Encoding)。对区域内的有效特征做掩码并叠加相对坐标投影,形成位置感知的对象token,为后续推理提供“这片语义在图像哪里”的线索。作者还为被裁剪/扩展后的区域加入相对位置编码来缓解对齐歧义,使对象token具备空间感知。
-
冗余聚合(Abundant Feature Aggregation)。对大/同质区域里高度相似的token,采用k-means 聚类合并,只保留n 个代表性token,既压缩冗余又保留多视角细节。这一步实证上显著降低了对象内部token的相似度,提高了表示“紧致度”。
PixelRefer-Lite (Object-Only Framework)
该变体仅使用对象标记进行 LLM 推理,借助对象中心信息融合模块(Object-Centric Infusion Module, OCI)将全局特征在前处理阶段融合入对象表示中。通过 Local-to-Object 和 Global-to-Object Attention,使目标的表征同时具备细节感知与全局语义,从而实现更完整的上下文融合。这样一来,推理阶段无需再使用全局视觉标记,显著降低显存与时间消耗,同时保持语义一致性与理解精度。

PixelRefer-Lite 实现了一个高效的推理框架,在保持高性能的同时将推理速度提升约 2–3 倍。
数据集
作者收集并开源了用于训练的两类数据集,分别是Foundational Object Perception(140万样本):涵盖物体、部件、时序关系的识别与描述以及Visual Instruction Tuning(80万样本):覆盖区域QA、视频QA、多对象关系与未来事件预测QA。
性能结果
-
对于图像像素级细粒度理解benchmark
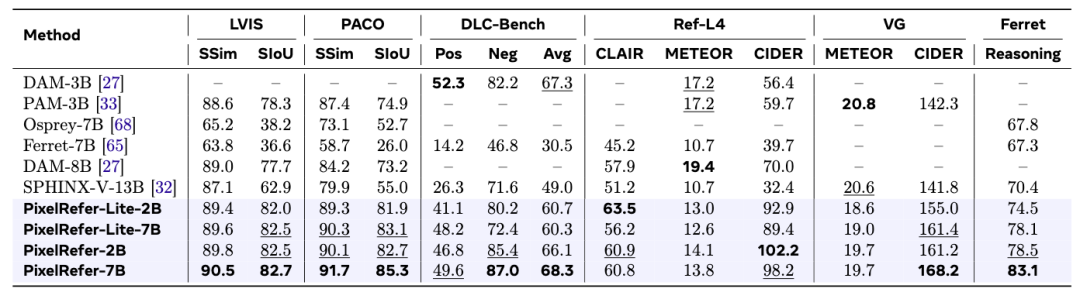
PixelRefer在多个图像理解benchmark上已达到SOTA水平,不论是简单的区域识别还是详细理解,已成为最先进的模型,特别是在reasoning场景下,更是展现出了突出优势。
-
对于视频像素级细粒度理解benchmark
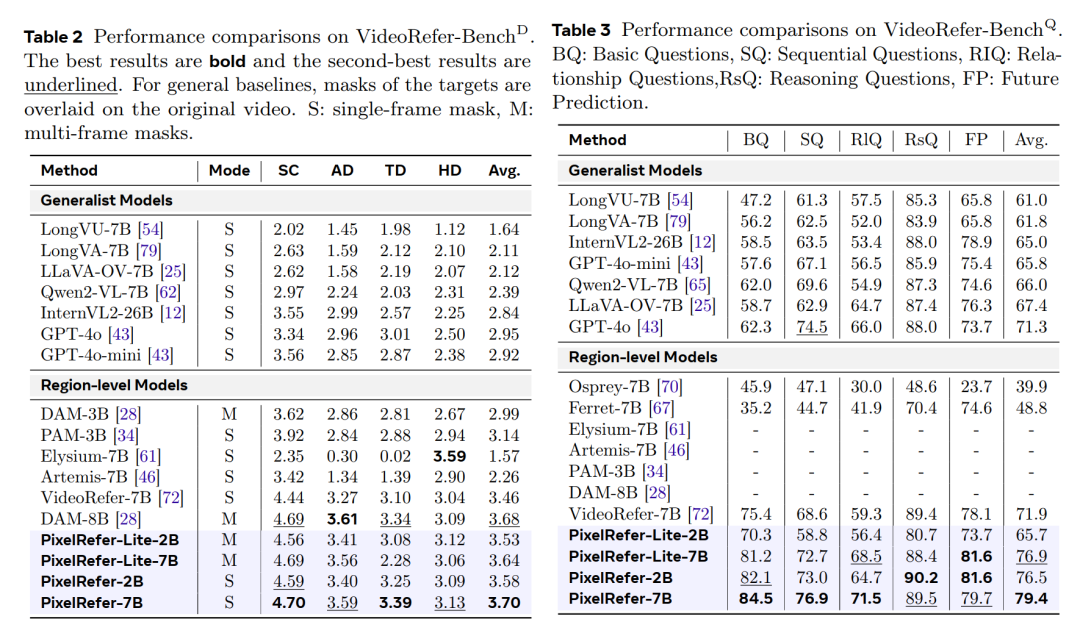
在经典的VideoRefer-Bench上,不论是视频区域的caption还是QA,均取得了领先性能,展现了通用而又全面的能力。
-
对于推理时间与效率的计算
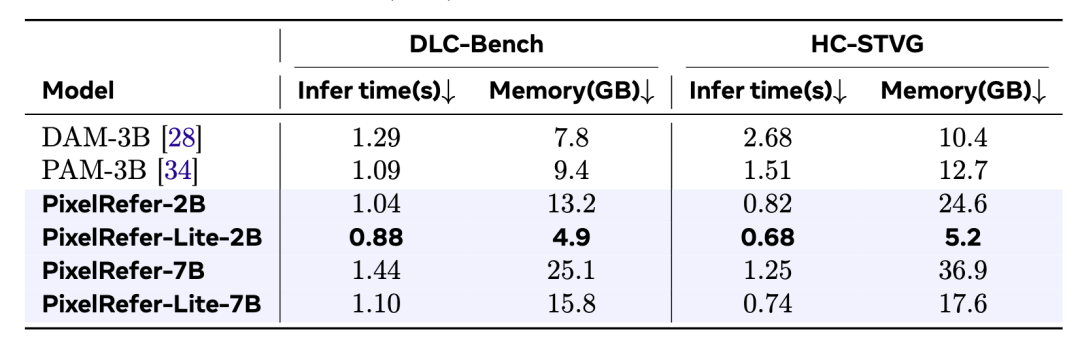
在基于图片的benchmark DLC-Bench和基于视频的benchmark上HC-STVG上均进行了测评,轻量版的PixelRefer-Lite-2B模型有较大的领先优势,特别是在视频上,相较于DAM-3B,推理时间缩短了约4倍,显存占用减少了2倍。
-
消融实验:Scale-adaptive Object Tokenizer vs MaskPooling
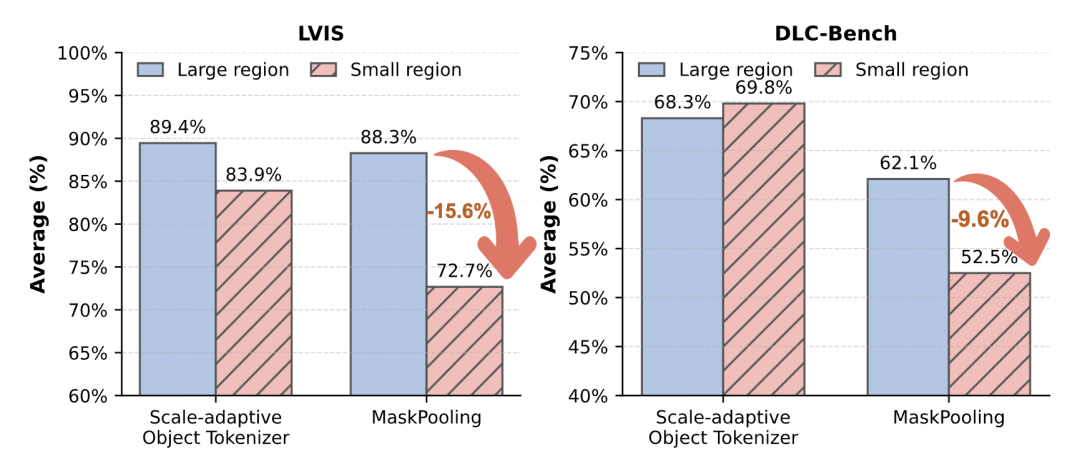
-
相较于之前简单maskpooling的做法,作者提出的Scale-adaptive Object Tokenizer模块有明显的提升,特别是在小目标理解上,在LVIS和DLC-Bench上均提升了十几个点。
-
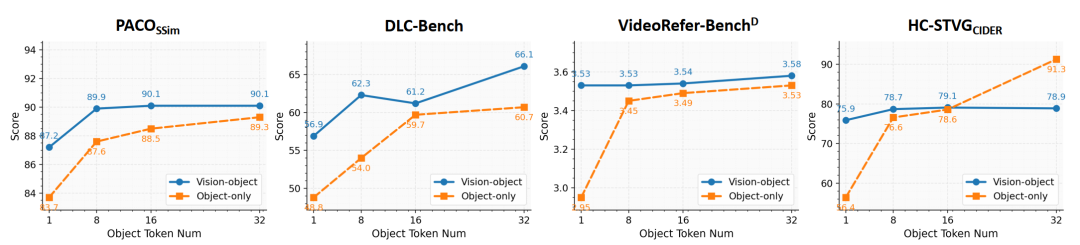
消融实验:对于区域token的表征个数
研究意义与总结
PixelRefer的出现,标志着AI视觉理解从“看懂一张图”迈向“理解世界的细节动态”,为多模态大模型的精细化视觉理解提供了新的方向。应用前景包括:
-
自动驾驶的时序场景识别
-
医疗影像的病灶级理解
-
智能视频剪辑与监控
-
多模态对话与人机交互
未来的多模态AI,不仅会“看见世界”,更会理解世界的关系。PixelRefer的提出,正是通向通用视觉智能的一块关键拼图。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com