Meta研究揭示,大语言模型仅凭文本训练,就能习得强大的视觉先验!推理数据是关键,能有效“磨砺”模型抽象思维,为构建未来多模态AI指明方向。
原文标题:读万卷书,大模型就能「看」懂视觉世界?Meta揭秘LLM视觉先验的起源
原文作者:机器之心
冷月清谈:
研究的核心洞察在于,LLM从语言中得到的“视觉先验”并非单一能力,而是可分解为两种截然不同的部分:
1. **推理先验 (Reasoning Prior)**:这是一种更抽象、跨模态的通用能力,主要通过预训练以推理为中心的数据(如代码、数学、学术论文)来获得。它赋予模型解决复杂视觉问题的普适推理框架。
2. **感知先验 (Perception Prior)**:这更侧重于对具体视觉概念的认知(如识别物体的颜色、形状、名称),它从广泛多样的通用语料(如网页抓取)中「弥散式」地浮现。感知能力的表现对视觉指令微调和视觉编码器更为敏感。
研究通过一系列精巧的实验证实了这些发现。他们发现,在预训练数据中,持续增加推理密集型文本(如代码)的比例,模型的下游视觉推理能力会显著提升,甚至能达到75%的占比。 与之形成对比的是,描述视觉世界的文本虽然重要,但其效果会迅速饱和,少量即可打下基础。
基于这些发现,研究团队进一步调配出了一套最优的数据混合方案,即“平衡配方”。该配方富含推理内容,并配以适量的视觉世界知识,可用于在语言预训练阶段就为模型注入强大的视觉先验。实验结果表明,按此配方训练出的模型在语言能力上与专门优化语言任务的模型持平或更优,同时在所有视觉基准测试中全面超越。
这项研究的意义深远,它将多模态模型能力的培养前移至语言预训练阶段,并支持了“柏拉图表征假说”,即通过一种模态的“投影”,模型也能学习到世界的统一内在结构。它为未来构建更强大的跨模态智能基础,指明了在LLM预训练阶段“播下视觉种子”的可能性。简单来说,让LLM变聪明的关键,不是让它死记硬背无数次“天空是蓝色的”,而是让它通过解决逻辑问题、理解代码来磨砺“脑子”。
怜星夜思:
2、文章主要聚焦于视觉问答(VQA)等任务。你认为这项研究对于其他更复杂的视觉或多模态任务,比如机器人导航、自动驾驶或者创意内容生成(如根据文本生成视频),会有怎样的启发和实际应用潜力?
3、文章提到了“柏拉图表征假说”,即文本和图像只是现实世界在不同模态下的“投影”,一个强大的模型可以仅从一种投影中学习到世界的统一内在结构。你觉得这对于我们理解人类大脑如何学习和形成抽象概念有什么启示?人类学习视觉世界,也像LLM一样,先通过语言建立一套推理框架吗?
原文内容

一个只见过文本的大语言模型(LLM),在从未直接看过图像的情况下,竟然能学到可迁移到视觉任务的先验能力 —— 这是 Meta Superintelligence Labs 与牛津团队新论文的发现。
近日,Meta 超级智能实验室(Meta Superintelligence Labs)与牛津大学的研究者发布了一篇长达 33 页的重磅论文,通过超过 100 组受控实验、耗费 50 万 GPU 小时的庞大研究,系统性地揭开了 LLM 视觉先验的来源。 作者提出,视觉先验可分为「推理先验」和「感知先验」,并给出了一套预训练的数据混合配方,用于在只用文本预训练阶段就「播下」视觉能力的种子。
这项研究不仅解释了 LLM 无师自通学会看的秘密,更提出了一套预训练的数据配方,旨在从语言预训练阶段就有意地培养模型的视觉能力,为下一代更强大的多模态大模型铺平道路。

-
论文标题:Learning to See Before Seeing: Demystifying LLM Visual Priors from Language Pre-training
-
论文链接:https://arxiv.org/pdf/2509.26625
-
项目地址:
https://junlinhan.github.io/projects/lsbs/
核心洞察:LLM 视觉先验并非铁板一块,源于两种独立的「先验知识」
研究最重要的发现是,LLM 从语言中获得的「视觉先验」(Visual Priors)并非单一的能力,而是可以分解为两种来源和特性截然不同的部分:
-
推理先验 (Reasoning Prior):一种更抽象、跨模态的通用能力。它主要通过预训练以推理为中心的数据(如代码、数学、学术论文)来获得。就像人类通过学习逻辑和数学来构建推理框架一样,LLM 通过学习这些结构化文本,掌握了可迁移的、普适的推理能力,这种能力可以直接应用于解决复杂的视觉问题。
-
感知先验 (Perception Prior):这更侧重于对具体视觉概念的认知,比如识别物体的颜色、形状和名称。这种能力并非来自某一特定类型的数据,而是从广泛、多样的通用语料(如网页抓取)中「弥散式」地浮现出来。多模态大模型的感知能力对视觉指令微调和所选用的视觉编码器更为敏感。
关键发现:少量视觉描述就够,海量推理数据是关键

大量实验:系统性揭秘 LLM 的视觉先验
团队进行了一系列精巧的实验,实验采用常见的 adapter-style 多模态适配流程 —— 先在只读文本的基础上预训练多种解码器式 LLM(沿用 Llama-3 风格架构,模型尺度从 340M 到 13B 不等,核心对比以 3B/7B 模型 为主),然后用同样的「视觉对齐 + 监督微调」的两阶段流程把视觉能力接入来衡量视觉先验,得出了 6 个结论并引入 3 个假设,这里节选:
-
能力的起源有迹可循:通过对 16 种不同单一数据源的独立训练,研究发现,在「代码」「数学」和「学术」数据上训练的模型,在需要抽象推理的视觉任务(Vision-Centric VQA)上表现最好。
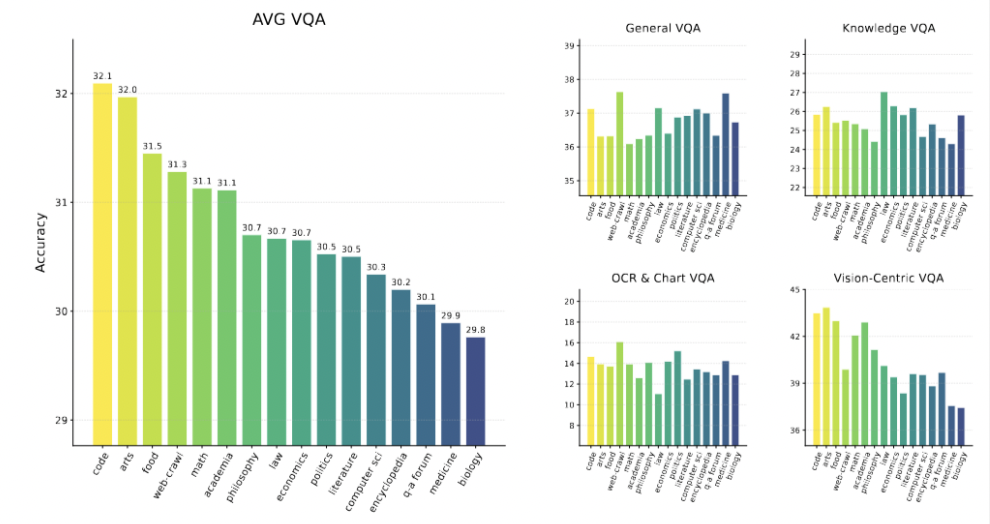
-
推理数据多多益善,视觉数据很快饱和:实验表明,在预训练数据中,不断增加推理密集型文本(如代码)的比例,模型的下游视觉推理能力会持续、显著地提升,直到占比达到 75% 左右。与此形成鲜明对比的是,描述视觉世界的文本(如描述颜色、形状、位置的文字)虽然重要,但其效果会迅速饱和。只需一小部分这类数据为模型打下基础,再多就收效甚微了。
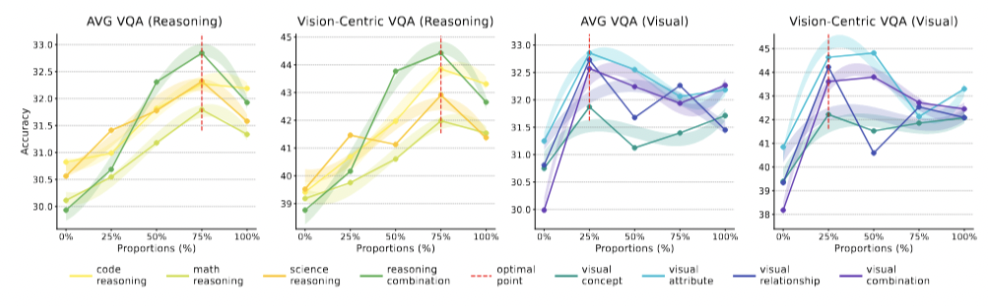
-
推理能力是通用的,感知能力更依赖「后天」:研究进一步证实,「推理先验」是独立于视觉编码器的通用能力。无论后期与哪种视觉模块结合,只要 LLM 在预训练阶段学到了强大的推理能力,其多模态系统的推理表现都会相应提升。而「感知先验」则不同,它更依赖于后期的视觉微调数据和视觉编码器本身的特性。
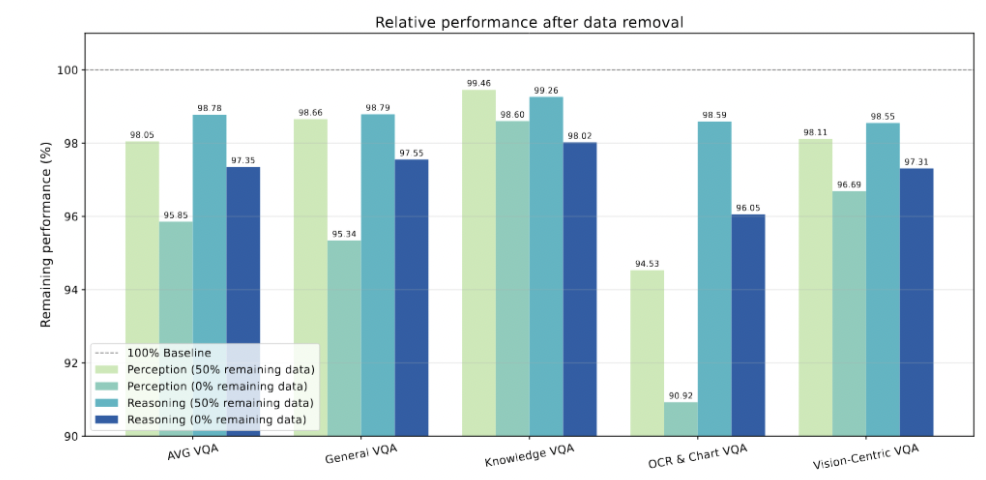
简单来说,想要让一个 LLM 拥有强大的视觉潜力,关键不是给它读无数遍「天空是蓝色的」,而是让它通过解数学题、读代码来把「脑子」练聪明。
从理论到实践:一份增强视觉先验的数据预训练配方
基于以上发现,研究团队的目标从「解释现象」转向了「主动创造」。他们通过系统的实验,最终调配出了一套最优的数据混合方案,旨在平衡模型的语言能力和视觉潜力。
实验结果表明,通过采用这种富含推理内容、同时配有适量视觉世界知识的「平衡配方」(Balanced model),训练出的 7B 模型在语言能力上与专门优化语言任务的预训配方训练的模型达到了更优,同时在所有视觉基准测试中都实现了全面超越。
这证明了,通过精心设计文本预训练数据,我们可以「未卜先知」地为模型注入强大的视觉先验。

意义与展望
这项研究的意义深远,它将多模态模型能力的培养,从依赖下游微调提前到了语言预训练阶段。
它展示了,核心的推理能力是一种可迁移、与模态无关的基石。这为「柏拉图表征假说」(Platonic Representation Hypothesis)提供了有力的经验支持 —— 即文本和图像只是现实世界在不同模态下的「投影」,一个足够强大的模型可以仅从一种投影中,学习到这个世界的统一内在结构。
未来,LLM 的预训练将不再仅仅是单模态的事。模型设计者从一开始就可以考虑其未来的多模态应用,通过在预训练阶段「播下视觉的种子」,来构建一个更强大的跨模态智能基础。
更多技术细节和实验分析,请参阅原论文。
作者介绍
韩俊霖(Junlin Han)是这篇论文的第一作者兼项目负责人。他目前是 Meta 超级智能实验室的研究员,同时也是牛津大学 Torr Vision Group 的博士生,师从 Philip Torr 教授。他的研究兴趣聚焦多模态智能系统,先后在跨模态数据生成、3D 生成模型等领域开展研究。此前,他以一等荣誉毕业于澳大利亚国立大学,曾在顶级会议多次发表重要研究成果并组织研讨会。
文章第二作者 Peter Tong(童晟邦 / Shengbang Tong),目前是纽约大学 Courant 计算机科学系的博士生,导师包括 Yann LeCun 和 Saining Xie。他曾在伯克利人工智能实验室 (BAIR) 进行本科研究,师从马毅教授。研究方向包括世界模型 (world model)、无监督 / 自监督学习、生成模型与多模态模型。他曾获得了 OpenAI Superalignment Fellowship 和 Meta 的博士项目资助。
第三作者 David Fan 现任 Meta FAIR 的高级研究工程师。他的研究方向集中在多模态表征学习、视频理解 / 自监督学习等领域。 在加入 FAIR 之前,他曾在 Amazon Prime Video 担任 Applied Research Scientist,参与视觉 - 语言 - 音频融合模型、视频理解和推荐系统等真实产品项目。他于普林斯顿大学获得计算机科学学位。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:liyazhou@jiqizhixin.com